文件名称:
消息队列kafka详解:如何实现死信队列.md
所在目录:
docs / mq / kafka
文件大小:
14.23 KB
下载地址:
文本预览:
### Apache Kafka 中用于错误处理的死信队列:来自 Uber 和 Crowdstrike 的替代方案、最佳实践和案例研究。
识别和处理错误对于任何可靠的数据流管道都是必不可少的。这篇博文探讨了** 在 Apache Kafka 基础架构中****使用死信队列实现错误处理的最佳实践**。这些选项包括自定义实现、Kafka Streams、Kafka Connect、Spring 框架和并行消费者。真实案例研究展示了 Uber、CrowdStrike 和桑坦德银行如何以极端规模构建可靠的实时错误处理。
Apache Kafka 成为许多企业架构最喜欢的集成中间件。即使对于云优先战略,企业也可以利用 Kafka 的数据流作为云原生集成平台即服务 (iPaaS)。
### Apache Kafka 数据流中的消息队列模式
在我开始这篇文章之前,我想让你知道这个内容是**关于“JMS、消息队列和 Apache Kafka”的博客系列**的一部分:
* JMS 消息代理与 Apache Kafka 数据流的**10 个比较标准**
* _**这篇文章**_**– 通过Apache Kafka 中的死信队列 (DQL)**进行错误处理的替代方法
* 使用 Apache Kafka实现**请求-回复模式**
* _即将_推出——**用于选择正确消息系统的决策树**(JMS 与 Apache Kafka)
* _即将推出_——从 JMS 消息代理到 Apache Kafka:**集成、迁移和/或替换**
### 什么是死信队列集成模式(在 Apache Kafka 中)?
**死信队列 (DLQ)**是消息系统或数据流平台内的一种服务实现,用于**存储未成功处理的消息**。系统不是被动地转储消息,而是将其移动到死信队列。
企业**集成模式 (EIP)**改为调用设计模式死信通道。我们可以将两者用作同义词。
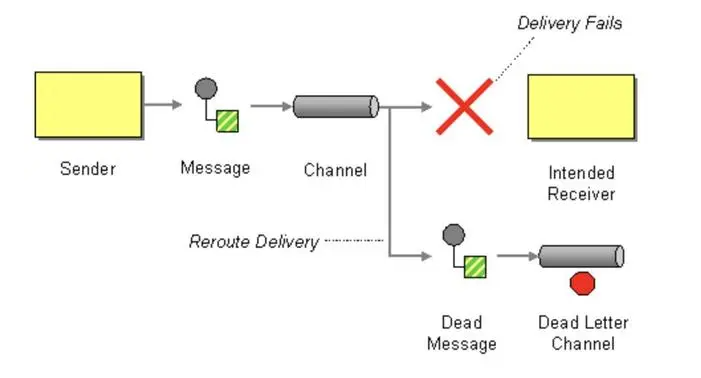
本文重点介绍数据流平台 Apache Kafka。**在 Kafka 中将消息放入 DLQ 的**主要原因通常是消息格式错误或消息内容无效/缺失。例如,如果预期值是整数,但生产者发送了字符串,则会发生应用程序错误。在更动态的环境中,“主题不存在”异常可能是无法传递消息的另一个错误。
因此,通常不要使用现有中间件经验中的知识。Message Queue 中间件(如符合 JMS 的 IBM MQ、TIBCO EMS 或 RabbitMQ)与分布式提交日志(如 Kafka)的工作方式不同。由于许多其他原因,消息队列中的 DLQ 用于消息队列系统,这些原因不能一对一地映射到 Kafka。例如,MQ 系统中的消息由于每条消息的 TTL(生存时间)而过期。
因此,**在 Kafka 中将消息放入 DLQ 的主要原因是消息格式错误或消息内容无效/缺失**。
### Apache Kafka 中死信队列的替代方案
Kafka 中的死信队列是一个或多个 Kafka 主题,它们**接收和存储由于错误而无法在另一个流管道中处理的消息**。此概念允许使用以下传入消息继续消息流,而不会由于无效消息的错误而停止工作流。
### Kafka Broker 很笨——智能端点提供错误处理
**Kafka 架构不支持 broker** r 中的DLQ。有意地,Kafka 建立在与现代微服务相同的原则上,使用“哑管道和智能端点”原则。这就是为什么与传统消息代理相比,Kafka 的扩展性如此之好。过滤和错误处理发生在客户端应用程序中。
数据流平台的真正解耦可以实现更干净的领域驱动设计。**每个微服务或应用程序都通过自己选择的技术、通信范式和错误处理来实现其逻辑**。
在传统的中间件和消息队列中,代理提供了这种逻辑。结果是域中的可扩展性和灵活性较差,因为只有中间件团队才能实现集成逻辑。
### 用任何编程语言自定义实现 Kafka 死信队列
Kafka 中的死信队列独立于您使用的框架。一些组件为错误处理和死信队列提供了开箱即用的功能。但是,使用Java、Go、C++、Python 等**任何编程语言为 Kafka 应用程序编写死信队列逻辑**也很容易。
**死信队列实现**的源代码包含一个 try-catch 块来处理预期或意外异常。如果没有发生错误,则处理该消息。如果发生任何异常,请将消息发送到专用的 DLQ Kafka 主题。
**失败原因应添加到 Kafka 消息的标头**中。不应更改键和值,以便将来对历史事件进行重新处理和故障分析。
### 死信队列的开箱即用 Kafka 实现
你并不总是需要实现你的死信队列。**许多组件和框架已经提供了它们的 DLQ 实现**。
使用您自己的应用程序,您通常可以控制错误或在出现错误时修复代码。但是,**与 3rd 方应用程序的集成并不一定允许您处理可能跨集成障碍引入的错误**。因此,DLQ 变得更加重要,并被包含在某些框架中。
### Kafka Connect 内置死信队列
**Kafka Connect 是 Kafka 的集成框架**。它包含在开源 Kafka 下载中。不需要其他依赖项(除了您部署到 Connect 集群中的连接器本身)。
默认情况下,如果由于使用无效消息而发生错误(例如使用错误的 JSON 转换器而不是正确的 AVRO 转换器时),Kafka Connect 任务将停止。删除无效消息是另一种选择。后者容忍错误。
Kafka Connect 中 DLQ 的配置很简单。只需将两个配置选项 ' errors.tolerance' 和 ' errors.deadletterqueue.topic.name' 的值设置为正确的值:
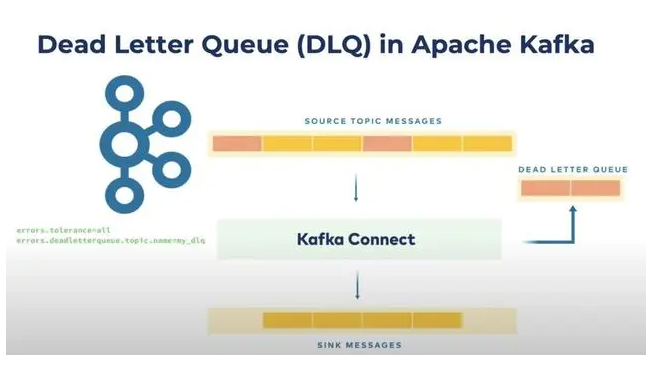
博客文章“ Kafka Connect Deep Dive – 错误处理和死信队列”显示了使用 DLQ 的详细动手代码示例。
**Kafka Connect 甚至可以用于处理 DLQ 中的错误消息**。只需部署另一个使用 te DLQ 主题的连接器。例如,如果您的应用程序处理 Avro 消息并且传入消息是 JSON 格式。然后连接器使用 JSON 消息并将其转换为 AVRO 消息以成功重新处理:
请注意,Kafka Connect **没有用于源连接器的死信队列**。
### Kafka Streams 应用程序中的错误处理
**Kafka Streams 是 Kafka 的流处理库**。它可与其他流式传输框架相媲美,例如 Apache Flink、Storm、Beam 和类似工具。但是,它是 Kafka 原生的。这意味着您可以在单个可扩展且可靠的基础架构中构建完整的端到端数据流。
如果您分别使用 Java(JVM 生态系统)来构建 Kafka 应用程序,**建议几乎总是使用 Kafka Streams 而不是 Kafka 的标准 Java 客户端**。为什么?
* Kafka Streams“只是”一个围绕常规 Java 生产者和消费者 API 的包装器,以及许多内置的附加功能。
* 两者都只是嵌入到 Java 应用程序中的库(JAR 文件)。
* 两者都是开源 Kafka 下载的一部分 - 没有额外的依赖项或许可证更改。
* 许多问题已经开箱即用地解决,以构建成熟的流处理服务(流功能、有状态的嵌入式存储、滑动窗口、交互式查询、错误处理等等)。
Kafka Streams的**内置功能之一是默认的反序列化异常处理程序**。它允许您管理无法反序列化的**记录异常。**损坏的数据、不正确的序列化逻辑或未处理的记录类型都可能导致错误。该功能不称为死信队列,但开箱即用地解决了相同的问题。
### Spring Kafka 和 Spring Cloud Stream 的错误处理
Spring 框架对 Apache Kafka 有很好的支持。它提供了许多模板以避免自己编写样板代码。**Spring-Kafka 和 Spring Cloud Stream Kafka 支持各种重试和错误处理选项**,包括基于时间/计数的重试、死信队列等。
尽管 Spring 框架功能非常丰富,但它有点重,并且有一个学习曲线。因此,它非常适合新建项目,或者如果您已经将 Spring 用于其他场景的项目。
有很多很棒的博客文章展示了不同的示例和配置选项。还有用于死信队列的官方 Spring Cloud Stream 示例。Spring 允许使用简单的注释构建逻辑,例如 DLQ。这种编程方法是一些开发人员钟爱的范例,而另一些则不喜欢它。只需了解选项并为自己选择合适的选项即可。
### Apache Kafka 并行消费者的可扩展处理和错误处理
在许多客户对话中,事实证明,**请求死信队列的主要原因通常是处理连接到外部 Web 服务或数据库的失败**。超时或 Kafka 无法并行发送各种请求会导致某些应用程序瘫痪。这个问题有一个很好的解决方案:
Apache Kafka的**并行消费者**是Apache 2.0 许可下**的开源项目。**它提供了一个带有客户端队列的并行 Apache Kafka 客户端包装器、一个具有**关键并发性的更简单的消费者/生产者 API,**以及**可扩展的非阻塞 IO**处理。
该库允许您**通过单个 Kafka Consumer 并行处理消息,这意味着您可以在不增加**要处理的主题中的分区数量的情况下增加 Kafka Consumer 并行度。**对于许多用例,这通过减少 Kafka 代理的负载来**提高吞吐量和延迟。它还开辟了新的用例,例如极端并行性、外部数据丰富和排队。
一个关键特性是**在单个 Kafka 消费者应用程序中处理/重复 Web 服务和数据库调用**。并行化避免了一次发送单个 Web 请求的需要:
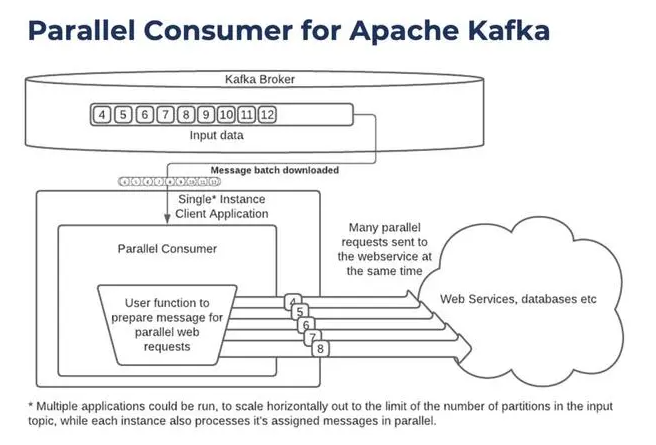
**Parallel Consumer 客户端具有强大的重试**逻辑。这包括可配置的延迟和动态错误或处理。错误也可以发送到死信队列。
### 使用死信队列中的消息
**将错误发送到死信队列后,您还没有完成!坏消息需要被处理或至少被监控!**
死信队列是**从事件处理中带外处理数据错误处理**的绝佳方式,这意味着错误处理程序可以与事件处理代码分开创建或演变。
存在大量使用死信队列的错误处理策略。DO 和 DONT 探索最佳实践和经验教训。
### 错误处理策略
有几个选项可用于处理存储在死信队列中的消息:
* **重新处理**:DLQ中的一些消息需要重新处理。但是,首先,需要解决这个问题。解决方案可以是自动脚本、编辑消息的人工交互,或向生产者返回错误,要求重新发送(更正的)消息。
* **删除错误消息(经过进一步分析)**:根据您的设置,可能会出现错误消息。但是,在删除它们之前,业务流程应该检查它们。例如,仪表板应用程序可以使用错误消息并将它们可视化。
* **高级分析**:另一种选择是分析传入数据以获取实时洞察或问题,而不是处理 DLQ 中的每条消息。例如,一个简单的 ksqlDB 应用程序可以应用流处理进行计算,例如每小时错误消息的平均数量或任何其他有助于确定 Kafka 应用程序中的错误的见解。
* **停止工作流**:如果很少会出现坏消息,结果可能是停止整个业务流程。该动作可以是自动的,也可以由人决定。当然,停止工作流也可以在抛出错误的 Kafka 应用程序中完成。如果需要,DLQ 将问题和决策外部化。
* **忽略**:这听起来可能是最糟糕的选择。只是让死信队列填满,什么都不做。然而,即使这样在某些用例中也很好,比如监控 Kafka 应用程序的整体行为。请记住,Kafka 主题具有保留时间,并且在该时间之后从主题中删除消息。只需为您设置正确的方式即可。并监控 DQL 主题是否存在意外行为(例如填充太快)。
### Apache Kafka 中死信队列的最佳实践
以下是在 Kafka 应用程序中使用死信队列进行错误处理的一些**最佳实践和经验教训:**
* 定义**处理无效消息的业务流程**(自动与人工)
* 现实:通常,根本没有人处理 DLQ 消息
* 备选方案 1:数据所有者需要接收警报,而不仅仅是基础架构团队
* 备选方案 2:警报应通知记录团队系统数据错误,他们将需要从记录系统重新发送/修复数据。
* 如果没有人关心或抱怨,请考虑质疑和审查 DLQ 存在的必要性。相反,这些消息也可以在初始 Kafka 应用程序中被忽略。这节省了大量的网络负载、基础设施和资金。
* 构建**带有适当警报的仪表板**并整合相关团队(例如,通过电子邮件或 Slack 警报)
* 定义每个 Kafka 主题的**错误处理优先级(停止、删除和重新处理)**
* **仅将不可重试的错误消息推送到 DLQ** - 连接问题是消费者应用程序的责任。
* **保留原始消息**并将它们存储在 DLQ 中(带有额外的标头,例如错误消息、错误时间、发生错误的应用程序名称等)——这使得重新处理和故障排除变得更加容易。
* **想想你需要多少 Dead Letter Queue Kafka 主题**。总是有取舍。但是将所有错误存储在单个 DLQ 中可能对进一步分析和重新处理没有意义。
请记住,**DLQ 会以有保证的顺序终止处理,并使任何类型的离线处理变得更加困难**。因此,Kafka DQL 并不适合每个用例。
### 何时不在 Kafka 中使用死信队列?
让我们探讨一下不应该将哪些类型的消息放入 Kafka 的死信队列中:
* **DLQ 用于背压处理?**由于大量消息的峰值而使用 DLQ 进行节流并不是一个好主意。Kafka 日志背后的存储会自动处理背压。消费者以它可以按自己的速度获取数据的方式提取数据(或者配置错误)。如果可能的话,弹性地扩展消费者。即使您的存储空间已满,DLQ 也无济于事。这是它的问题,与是否使用 DLQ 无关。
* **连接失败的DLQ?**由于连接失败而将消息放入 DQL 无济于事(即使在多次重试之后)。以下消息也无法连接到该系统。您需要解决连接问题。消息可以根据需要存储在常规主题中(取决于保留时间)。
### 用于数据治理和错误预防的模式注册表
最后但同样重要的是,让我们探讨在某些情况下**减少甚至消除对死信队列的需求的可能性。**
**卡夫卡**的Schema Registry**是一种确保数据清理以防止生产者在负载中出错的方法**。它在 Kafka 生产者中强制执行正确的消息结构:
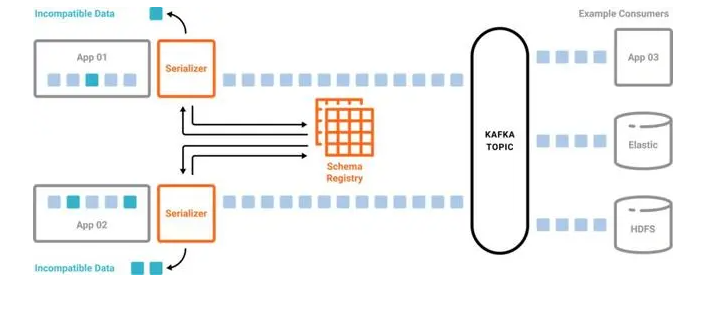
模式注册表是模式的客户端检查。Confluent Server 等一些实现在代理端提供了额外的模式检查,以拒绝来自未使用模式注册表的生产者的无效或恶意消息。
### Kafka 死信队列的案例研究
让我们看看**Uber、CrowdStrike 和 Santander Bank 的三个案例研究,它们在 Kafka 基础设施中实际部署死信队列**。请记住,这些都是非常成熟的例子。不是每个项目都需要那么复杂。
### Uber - 构建可靠的再处理和死信队列
在分布式系统中,重试是不可避免的。从网络错误到复制问题,甚至下游依赖关系的中断,大规模运行的服务必须准备好尽可能优雅地遇到、识别和处理故障。
鉴于 Uber 的运营范围和速度,它的系统必须具有**容错能力,并且在智能失败时毫不妥协**。Uber 将 Apache Kafka 用于各种极端规模的用例以实现这一目标。
利用这些特性,Uber 保险工程团队扩展了 Kafka 在其现有事件驱动架构中的作用,通过使用 n**个阻塞请求重新处理和死信队列来实现解耦、可观察的错误处理,而不会中断实时流量**。该策略有助于他们选择加入的驾驶员伤害保护计划在 200 多个城市可靠运行,并为注册驾驶员扣除每次行程的每英里保费。
这是 Uber 错误处理的示例。错误会降低重试主题的级别,直到登陆 DLQ:
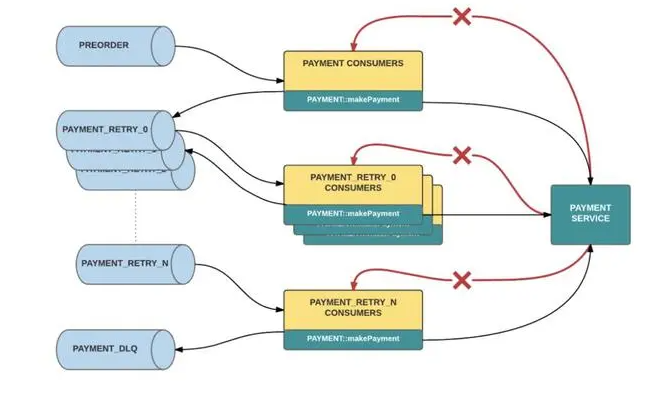
有关更多信息,请阅读 Uber 非常详细的技术文章:“使用 Apache Kafka 构建可靠的再处理和死信队列”。
### CrowdStrike - 处理数万亿事件的错误
CrowdStrike 是一家位于德克萨斯州奥斯汀的**网络安全技术公司。**它提供**云工作负载和端点安全、威胁情报和网络攻击响应服务**。
CrowdStrike 的基础设施** 每天使用 Apache Kafka 处理数万亿个事件**。在我的“ Apache Kaka 网络安全博客系列”中,我介绍了以任何规模实时创建态势感知和威胁情报的相关用例。
CrowdStrike 定义了三个最佳实践 来成功实现死信队列和错误处理:
* **在正确的系统中存储错误消息**:定义基础设施和代码以捕获和检索死信。CrowdStrike 使用 S3 对象存储来存储潜在的大量错误消息。请注意,Kafka 的分层存储开箱即用地解决了这个问题,无需其他存储接口(例如,利用 Confluent Cloud 中的无限存储)。
* **使用自动化**:放置工具以使修复万无一失,因为手动完成错误处理可能非常容易出错。
* **记录业务流程并聘请相关团队**:标准化和记录流程以确保易于使用。并非所有工程师都熟悉组织处理死信消息的策略。
在**像 CrowdStrike 这样的网络安全平台中,大规模实时数据处理至关重要**。此要求也适用于错误处理。**下一次网络攻击可能是故意包含不适当或无效内容的恶意消息**(如 JavaScript 漏洞利用)。因此,必须通过死信队列实时处理错误。
### 桑坦德银行 - 用于重试和 DLQ 组合的邮箱 2.0
桑坦德银行**在邮箱应用程序中处理海量数据的同步数据处理面临巨大挑战**。他们重新架构了他们的基础架构并构建了一个解耦且可扩展的架构,称为“Santander Mailbox 2.0”。
Santander 的工作负载并转移到**由 Apache Kafka 提供支持的事件溯源**:
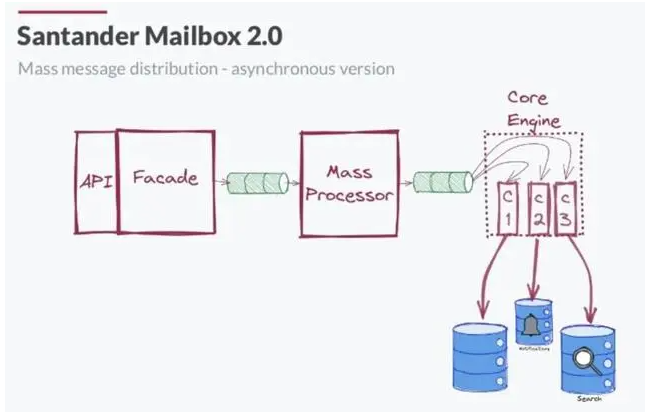
新的基于异步事件的架构中的一个关键挑战是错误处理。** Santander 使用重试和 DQL Kafka 主题构建的错误处理**解决了这些问题:
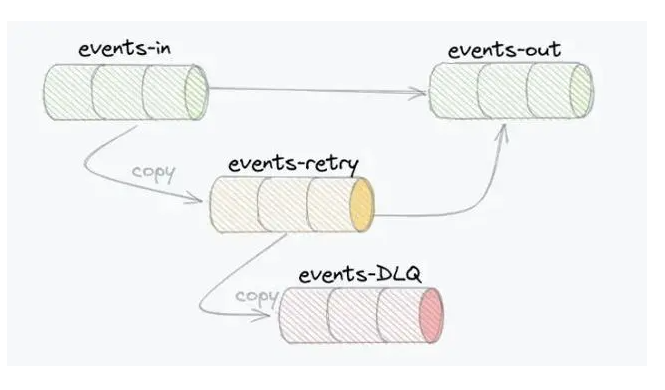
查看来自 Santander 的集成合作伙伴 Consdata的 Kafka 峰会演讲“基于重试策略和死信主题的 Apache Kafka 中的可靠事件传递”中的详细信息。
### Apache Kafka 中可靠且可扩展的错误处理
**错误处理对于构建可靠的数据流管道和平台至关重要**。存在不同的替代方案来解决这个问题。该解决方案包括死信队列的自定义实现或利用正在使用的框架,例如 Kafka Streams、Kafka Connect、Spring 框架或 Kafka 的并行消费者。
优步、CrowdStrike 和桑坦德银行的案例研究表明,错误处理并不总是很容易实现。当您设计新的应用程序或架构时,需要从一开始就考虑到这一点。**使用 Apache Kafka 进行实时数据流传输很有吸引力,但只有在您能够处理意外行为时才能成功**。死信队列是许多场景的绝佳选择。
识别和处理错误对于任何可靠的数据流管道都是必不可少的。这篇博文探讨了** 在 Apache Kafka 基础架构中****使用死信队列实现错误处理的最佳实践**。这些选项包括自定义实现、Kafka Streams、Kafka Connect、Spring 框架和并行消费者。真实案例研究展示了 Uber、CrowdStrike 和桑坦德银行如何以极端规模构建可靠的实时错误处理。
Apache Kafka 成为许多企业架构最喜欢的集成中间件。即使对于云优先战略,企业也可以利用 Kafka 的数据流作为云原生集成平台即服务 (iPaaS)。
### Apache Kafka 数据流中的消息队列模式
在我开始这篇文章之前,我想让你知道这个内容是**关于“JMS、消息队列和 Apache Kafka”的博客系列**的一部分:
* JMS 消息代理与 Apache Kafka 数据流的**10 个比较标准**
* _**这篇文章**_**– 通过Apache Kafka 中的死信队列 (DQL)**进行错误处理的替代方法
* 使用 Apache Kafka实现**请求-回复模式**
* _即将_推出——**用于选择正确消息系统的决策树**(JMS 与 Apache Kafka)
* _即将推出_——从 JMS 消息代理到 Apache Kafka:**集成、迁移和/或替换**
### 什么是死信队列集成模式(在 Apache Kafka 中)?
**死信队列 (DLQ)**是消息系统或数据流平台内的一种服务实现,用于**存储未成功处理的消息**。系统不是被动地转储消息,而是将其移动到死信队列。
企业**集成模式 (EIP)**改为调用设计模式死信通道。我们可以将两者用作同义词。

本文重点介绍数据流平台 Apache Kafka。**在 Kafka 中将消息放入 DLQ 的**主要原因通常是消息格式错误或消息内容无效/缺失。例如,如果预期值是整数,但生产者发送了字符串,则会发生应用程序错误。在更动态的环境中,“主题不存在”异常可能是无法传递消息的另一个错误。
因此,通常不要使用现有中间件经验中的知识。Message Queue 中间件(如符合 JMS 的 IBM MQ、TIBCO EMS 或 RabbitMQ)与分布式提交日志(如 Kafka)的工作方式不同。由于许多其他原因,消息队列中的 DLQ 用于消息队列系统,这些原因不能一对一地映射到 Kafka。例如,MQ 系统中的消息由于每条消息的 TTL(生存时间)而过期。
因此,**在 Kafka 中将消息放入 DLQ 的主要原因是消息格式错误或消息内容无效/缺失**。
### Apache Kafka 中死信队列的替代方案
Kafka 中的死信队列是一个或多个 Kafka 主题,它们**接收和存储由于错误而无法在另一个流管道中处理的消息**。此概念允许使用以下传入消息继续消息流,而不会由于无效消息的错误而停止工作流。
### Kafka Broker 很笨——智能端点提供错误处理
**Kafka 架构不支持 broker** r 中的DLQ。有意地,Kafka 建立在与现代微服务相同的原则上,使用“哑管道和智能端点”原则。这就是为什么与传统消息代理相比,Kafka 的扩展性如此之好。过滤和错误处理发生在客户端应用程序中。
数据流平台的真正解耦可以实现更干净的领域驱动设计。**每个微服务或应用程序都通过自己选择的技术、通信范式和错误处理来实现其逻辑**。
在传统的中间件和消息队列中,代理提供了这种逻辑。结果是域中的可扩展性和灵活性较差,因为只有中间件团队才能实现集成逻辑。
### 用任何编程语言自定义实现 Kafka 死信队列
Kafka 中的死信队列独立于您使用的框架。一些组件为错误处理和死信队列提供了开箱即用的功能。但是,使用Java、Go、C++、Python 等**任何编程语言为 Kafka 应用程序编写死信队列逻辑**也很容易。
**死信队列实现**的源代码包含一个 try-catch 块来处理预期或意外异常。如果没有发生错误,则处理该消息。如果发生任何异常,请将消息发送到专用的 DLQ Kafka 主题。
**失败原因应添加到 Kafka 消息的标头**中。不应更改键和值,以便将来对历史事件进行重新处理和故障分析。
### 死信队列的开箱即用 Kafka 实现
你并不总是需要实现你的死信队列。**许多组件和框架已经提供了它们的 DLQ 实现**。
使用您自己的应用程序,您通常可以控制错误或在出现错误时修复代码。但是,**与 3rd 方应用程序的集成并不一定允许您处理可能跨集成障碍引入的错误**。因此,DLQ 变得更加重要,并被包含在某些框架中。
### Kafka Connect 内置死信队列
**Kafka Connect 是 Kafka 的集成框架**。它包含在开源 Kafka 下载中。不需要其他依赖项(除了您部署到 Connect 集群中的连接器本身)。
默认情况下,如果由于使用无效消息而发生错误(例如使用错误的 JSON 转换器而不是正确的 AVRO 转换器时),Kafka Connect 任务将停止。删除无效消息是另一种选择。后者容忍错误。
Kafka Connect 中 DLQ 的配置很简单。只需将两个配置选项 ' errors.tolerance' 和 ' errors.deadletterqueue.topic.name' 的值设置为正确的值:

博客文章“ Kafka Connect Deep Dive – 错误处理和死信队列”显示了使用 DLQ 的详细动手代码示例。
**Kafka Connect 甚至可以用于处理 DLQ 中的错误消息**。只需部署另一个使用 te DLQ 主题的连接器。例如,如果您的应用程序处理 Avro 消息并且传入消息是 JSON 格式。然后连接器使用 JSON 消息并将其转换为 AVRO 消息以成功重新处理:
请注意,Kafka Connect **没有用于源连接器的死信队列**。
### Kafka Streams 应用程序中的错误处理
**Kafka Streams 是 Kafka 的流处理库**。它可与其他流式传输框架相媲美,例如 Apache Flink、Storm、Beam 和类似工具。但是,它是 Kafka 原生的。这意味着您可以在单个可扩展且可靠的基础架构中构建完整的端到端数据流。
如果您分别使用 Java(JVM 生态系统)来构建 Kafka 应用程序,**建议几乎总是使用 Kafka Streams 而不是 Kafka 的标准 Java 客户端**。为什么?
* Kafka Streams“只是”一个围绕常规 Java 生产者和消费者 API 的包装器,以及许多内置的附加功能。
* 两者都只是嵌入到 Java 应用程序中的库(JAR 文件)。
* 两者都是开源 Kafka 下载的一部分 - 没有额外的依赖项或许可证更改。
* 许多问题已经开箱即用地解决,以构建成熟的流处理服务(流功能、有状态的嵌入式存储、滑动窗口、交互式查询、错误处理等等)。
Kafka Streams的**内置功能之一是默认的反序列化异常处理程序**。它允许您管理无法反序列化的**记录异常。**损坏的数据、不正确的序列化逻辑或未处理的记录类型都可能导致错误。该功能不称为死信队列,但开箱即用地解决了相同的问题。
### Spring Kafka 和 Spring Cloud Stream 的错误处理
Spring 框架对 Apache Kafka 有很好的支持。它提供了许多模板以避免自己编写样板代码。**Spring-Kafka 和 Spring Cloud Stream Kafka 支持各种重试和错误处理选项**,包括基于时间/计数的重试、死信队列等。
尽管 Spring 框架功能非常丰富,但它有点重,并且有一个学习曲线。因此,它非常适合新建项目,或者如果您已经将 Spring 用于其他场景的项目。
有很多很棒的博客文章展示了不同的示例和配置选项。还有用于死信队列的官方 Spring Cloud Stream 示例。Spring 允许使用简单的注释构建逻辑,例如 DLQ。这种编程方法是一些开发人员钟爱的范例,而另一些则不喜欢它。只需了解选项并为自己选择合适的选项即可。
### Apache Kafka 并行消费者的可扩展处理和错误处理
在许多客户对话中,事实证明,**请求死信队列的主要原因通常是处理连接到外部 Web 服务或数据库的失败**。超时或 Kafka 无法并行发送各种请求会导致某些应用程序瘫痪。这个问题有一个很好的解决方案:
Apache Kafka的**并行消费者**是Apache 2.0 许可下**的开源项目。**它提供了一个带有客户端队列的并行 Apache Kafka 客户端包装器、一个具有**关键并发性的更简单的消费者/生产者 API,**以及**可扩展的非阻塞 IO**处理。
该库允许您**通过单个 Kafka Consumer 并行处理消息,这意味着您可以在不增加**要处理的主题中的分区数量的情况下增加 Kafka Consumer 并行度。**对于许多用例,这通过减少 Kafka 代理的负载来**提高吞吐量和延迟。它还开辟了新的用例,例如极端并行性、外部数据丰富和排队。
一个关键特性是**在单个 Kafka 消费者应用程序中处理/重复 Web 服务和数据库调用**。并行化避免了一次发送单个 Web 请求的需要:

**Parallel Consumer 客户端具有强大的重试**逻辑。这包括可配置的延迟和动态错误或处理。错误也可以发送到死信队列。
### 使用死信队列中的消息
**将错误发送到死信队列后,您还没有完成!坏消息需要被处理或至少被监控!**
死信队列是**从事件处理中带外处理数据错误处理**的绝佳方式,这意味着错误处理程序可以与事件处理代码分开创建或演变。
存在大量使用死信队列的错误处理策略。DO 和 DONT 探索最佳实践和经验教训。
### 错误处理策略
有几个选项可用于处理存储在死信队列中的消息:
* **重新处理**:DLQ中的一些消息需要重新处理。但是,首先,需要解决这个问题。解决方案可以是自动脚本、编辑消息的人工交互,或向生产者返回错误,要求重新发送(更正的)消息。
* **删除错误消息(经过进一步分析)**:根据您的设置,可能会出现错误消息。但是,在删除它们之前,业务流程应该检查它们。例如,仪表板应用程序可以使用错误消息并将它们可视化。
* **高级分析**:另一种选择是分析传入数据以获取实时洞察或问题,而不是处理 DLQ 中的每条消息。例如,一个简单的 ksqlDB 应用程序可以应用流处理进行计算,例如每小时错误消息的平均数量或任何其他有助于确定 Kafka 应用程序中的错误的见解。
* **停止工作流**:如果很少会出现坏消息,结果可能是停止整个业务流程。该动作可以是自动的,也可以由人决定。当然,停止工作流也可以在抛出错误的 Kafka 应用程序中完成。如果需要,DLQ 将问题和决策外部化。
* **忽略**:这听起来可能是最糟糕的选择。只是让死信队列填满,什么都不做。然而,即使这样在某些用例中也很好,比如监控 Kafka 应用程序的整体行为。请记住,Kafka 主题具有保留时间,并且在该时间之后从主题中删除消息。只需为您设置正确的方式即可。并监控 DQL 主题是否存在意外行为(例如填充太快)。
### Apache Kafka 中死信队列的最佳实践
以下是在 Kafka 应用程序中使用死信队列进行错误处理的一些**最佳实践和经验教训:**
* 定义**处理无效消息的业务流程**(自动与人工)
* 现实:通常,根本没有人处理 DLQ 消息
* 备选方案 1:数据所有者需要接收警报,而不仅仅是基础架构团队
* 备选方案 2:警报应通知记录团队系统数据错误,他们将需要从记录系统重新发送/修复数据。
* 如果没有人关心或抱怨,请考虑质疑和审查 DLQ 存在的必要性。相反,这些消息也可以在初始 Kafka 应用程序中被忽略。这节省了大量的网络负载、基础设施和资金。
* 构建**带有适当警报的仪表板**并整合相关团队(例如,通过电子邮件或 Slack 警报)
* 定义每个 Kafka 主题的**错误处理优先级(停止、删除和重新处理)**
* **仅将不可重试的错误消息推送到 DLQ** - 连接问题是消费者应用程序的责任。
* **保留原始消息**并将它们存储在 DLQ 中(带有额外的标头,例如错误消息、错误时间、发生错误的应用程序名称等)——这使得重新处理和故障排除变得更加容易。
* **想想你需要多少 Dead Letter Queue Kafka 主题**。总是有取舍。但是将所有错误存储在单个 DLQ 中可能对进一步分析和重新处理没有意义。
请记住,**DLQ 会以有保证的顺序终止处理,并使任何类型的离线处理变得更加困难**。因此,Kafka DQL 并不适合每个用例。
### 何时不在 Kafka 中使用死信队列?
让我们探讨一下不应该将哪些类型的消息放入 Kafka 的死信队列中:
* **DLQ 用于背压处理?**由于大量消息的峰值而使用 DLQ 进行节流并不是一个好主意。Kafka 日志背后的存储会自动处理背压。消费者以它可以按自己的速度获取数据的方式提取数据(或者配置错误)。如果可能的话,弹性地扩展消费者。即使您的存储空间已满,DLQ 也无济于事。这是它的问题,与是否使用 DLQ 无关。
* **连接失败的DLQ?**由于连接失败而将消息放入 DQL 无济于事(即使在多次重试之后)。以下消息也无法连接到该系统。您需要解决连接问题。消息可以根据需要存储在常规主题中(取决于保留时间)。
### 用于数据治理和错误预防的模式注册表
最后但同样重要的是,让我们探讨在某些情况下**减少甚至消除对死信队列的需求的可能性。**
**卡夫卡**的Schema Registry**是一种确保数据清理以防止生产者在负载中出错的方法**。它在 Kafka 生产者中强制执行正确的消息结构:

模式注册表是模式的客户端检查。Confluent Server 等一些实现在代理端提供了额外的模式检查,以拒绝来自未使用模式注册表的生产者的无效或恶意消息。
### Kafka 死信队列的案例研究
让我们看看**Uber、CrowdStrike 和 Santander Bank 的三个案例研究,它们在 Kafka 基础设施中实际部署死信队列**。请记住,这些都是非常成熟的例子。不是每个项目都需要那么复杂。
### Uber - 构建可靠的再处理和死信队列
在分布式系统中,重试是不可避免的。从网络错误到复制问题,甚至下游依赖关系的中断,大规模运行的服务必须准备好尽可能优雅地遇到、识别和处理故障。
鉴于 Uber 的运营范围和速度,它的系统必须具有**容错能力,并且在智能失败时毫不妥协**。Uber 将 Apache Kafka 用于各种极端规模的用例以实现这一目标。
利用这些特性,Uber 保险工程团队扩展了 Kafka 在其现有事件驱动架构中的作用,通过使用 n**个阻塞请求重新处理和死信队列来实现解耦、可观察的错误处理,而不会中断实时流量**。该策略有助于他们选择加入的驾驶员伤害保护计划在 200 多个城市可靠运行,并为注册驾驶员扣除每次行程的每英里保费。
这是 Uber 错误处理的示例。错误会降低重试主题的级别,直到登陆 DLQ:

有关更多信息,请阅读 Uber 非常详细的技术文章:“使用 Apache Kafka 构建可靠的再处理和死信队列”。
### CrowdStrike - 处理数万亿事件的错误
CrowdStrike 是一家位于德克萨斯州奥斯汀的**网络安全技术公司。**它提供**云工作负载和端点安全、威胁情报和网络攻击响应服务**。
CrowdStrike 的基础设施** 每天使用 Apache Kafka 处理数万亿个事件**。在我的“ Apache Kaka 网络安全博客系列”中,我介绍了以任何规模实时创建态势感知和威胁情报的相关用例。
CrowdStrike 定义了三个最佳实践 来成功实现死信队列和错误处理:
* **在正确的系统中存储错误消息**:定义基础设施和代码以捕获和检索死信。CrowdStrike 使用 S3 对象存储来存储潜在的大量错误消息。请注意,Kafka 的分层存储开箱即用地解决了这个问题,无需其他存储接口(例如,利用 Confluent Cloud 中的无限存储)。
* **使用自动化**:放置工具以使修复万无一失,因为手动完成错误处理可能非常容易出错。
* **记录业务流程并聘请相关团队**:标准化和记录流程以确保易于使用。并非所有工程师都熟悉组织处理死信消息的策略。
在**像 CrowdStrike 这样的网络安全平台中,大规模实时数据处理至关重要**。此要求也适用于错误处理。**下一次网络攻击可能是故意包含不适当或无效内容的恶意消息**(如 JavaScript 漏洞利用)。因此,必须通过死信队列实时处理错误。
### 桑坦德银行 - 用于重试和 DLQ 组合的邮箱 2.0
桑坦德银行**在邮箱应用程序中处理海量数据的同步数据处理面临巨大挑战**。他们重新架构了他们的基础架构并构建了一个解耦且可扩展的架构,称为“Santander Mailbox 2.0”。
Santander 的工作负载并转移到**由 Apache Kafka 提供支持的事件溯源**:

新的基于异步事件的架构中的一个关键挑战是错误处理。** Santander 使用重试和 DQL Kafka 主题构建的错误处理**解决了这些问题:

查看来自 Santander 的集成合作伙伴 Consdata的 Kafka 峰会演讲“基于重试策略和死信主题的 Apache Kafka 中的可靠事件传递”中的详细信息。
### Apache Kafka 中可靠且可扩展的错误处理
**错误处理对于构建可靠的数据流管道和平台至关重要**。存在不同的替代方案来解决这个问题。该解决方案包括死信队列的自定义实现或利用正在使用的框架,例如 Kafka Streams、Kafka Connect、Spring 框架或 Kafka 的并行消费者。
优步、CrowdStrike 和桑坦德银行的案例研究表明,错误处理并不总是很容易实现。当您设计新的应用程序或架构时,需要从一开始就考虑到这一点。**使用 Apache Kafka 进行实时数据流传输很有吸引力,但只有在您能够处理意外行为时才能成功**。死信队列是许多场景的绝佳选择。
点赞
回复
X