文件名称:
02.分布式系统.md
所在目录:
杂记 / 读书笔记 / 左耳听风
文件大小:
38.19 KB
下载地址:
文本预览:
## 传统单体架构和分布式服务化架构的区别

**存在的问题:**
- 架构设计变得复杂(尤其是其中的分布式事务)。
- 部署单个服务会比较快,但是如果一次部署需要多个服务,流程会变得复杂。
- 系统的吞吐量会变大,但是响应时间会变长。
- 运维复杂度会因为服务变多而变得很复杂。
- 架构复杂导致学习曲线变大。
- 测试和查错的复杂度增大。
- 技术多元化,这会带来维护和运维的复杂度。
- 管理分布式系统中的服务和调度变得困难和复杂。
## 分布式系统的目的以及相关技术
**构建分布式系统的目的是增加系统容量,提高系统的可用性,转换成技术方面,也就是完成下面两件事。**
- **大流量处理。**通过集群技术把大规模并发请求的负载分散到不同的机器上。
- **关键业务保护。**提高后台服务的可用性,把故障隔离起来阻止多米诺骨牌效应(雪崩效应)。如果流量过大,需要对业务降级,以保护关键业务流转。
### 提高架构的性能

- **缓存系统。**加入缓存系统,可以有效地提高系统的访问能力。从前端的浏览器,到网络,再到后端的服务,底层的数据库、文件系统、硬盘和 CPU,全都有缓存,这是提高快速访问能力最有效的手段。对于分布式系统下的缓存系统,需要的是一个缓存集群。这其中需要一个 Proxy 来做缓存的分片和路由。
- **负载均衡系统。**负载均衡系统是水平扩展的关键技术,它可以使用多台机器来共同分担一部分流量请求。
- **异步调用。**异步系统主要通过消息队列来对请求做排队处理,这样可以把前端的请求的峰值给“削平”了,而后端通过自己能够处理的速度来处理请求。这样可以增加系统的吞吐量,但是实时性就差很多了。同时,还会引入消息丢失的问题,所以要对消息做持久化,这会造成“有状态”的结点,从而增加了服务调度的难度。
- **数据分区和数据镜像。数据分区**是把数据按一定的方式分成多个区(比如通过地理位置),不同的数据区来分担不同区的流量。这需要一个数据路由的中间件,会导致跨库的 Join 和跨库的事务非常复杂。而**数据镜像**是把一个数据库镜像成多份一样的数据,这样就不需要数据路由的中间件了。你可以在任意结点上进行读写,内部会自行同步数据。然而,数据镜像中最大的问题就是数据的一致性问题。
### 提高架构的稳定性

- **服务拆分。**服务拆分主要有两个目的:一是为了隔离故障,二是为了重用服务模块。但服务拆分完之后,会引入服务调用间的依赖问题。
- **服务冗余。**服务冗余是为了去除单点故障,并可以支持服务的弹性伸缩,以及故障迁移。然而,对于一些有状态的服务来说,冗余这些有状态的服务带来了更高的复杂性。其中一个是弹性伸缩时,需要考虑数据的复制或是重新分片,迁移的时候还要迁移数据到其它机器上。
- **限流降级。**当系统实在扛不住压力时,只能通过限流或者功能降级的方式来停掉一部分服务,或是拒绝一部分用户,以确保整个架构不会挂掉。这些技术属于保护措施。
- **高可用架构。**通常来说高可用架构是从冗余架构的角度来保障可用性。比如,多租户隔离,灾备多活,或是数据可以在其中复制保持一致性的集群。总之,就是为了不出单点故障。
- **高可用运维。**高可用运维指的是 DevOps 中的 CI/CD(持续集成 / 持续部署)。一个良好的运维应该是一条很流畅的软件发布管线,其中做了足够的自动化测试,还可以做相应的灰度发布,以及对线上系统的自动化控制。这样,可以做到“计划内”或是“非计划内”的宕机事件的时长最短。
### 分布式系统的关键技术
- **服务治理。**服务拆分、服务调用、服务发现、服务依赖、服务的关键度定义……服务治理的最大意义是需要把服务间的依赖关系、服务调用链,以及关键的服务给梳理出来,并对这些服务进行性能和可用性方面的管理。
- **架构软件管理。**服务之间有依赖,而且有兼容性问题,所以,整体服务所形成的架构需要有架构版本管理、整体架构的生命周期管理,以及对服务的编排、聚合、事务处理等服务调度功能。
- **DevOps。**分布式系统可以更为快速地更新服务,但是对于服务的测试和部署都会是挑战。所以,还需要 DevOps 的全流程,其中包括环境构建、持续集成、持续部署等。
- **自动化运维。**有了 DevOps 后,我们就可以对服务进行自动伸缩、故障迁移、配置管理、状态管理等一系列的自动化运维技术了。
- **资源调度管理。**应用层的自动化运维需要基础层的调度支持,也就是云计算 IaaS 层的计算、存储、网络等资源调度、隔离和管理。
- **整体架构监控。**如果没有一个好的监控系统,那么自动化运维和资源调度管理只可能成为一个泡影,因为监控系统是你的眼睛。没有眼睛,没有数据,就无法进行高效运维。所以说,监控是非常重要的部分。这里的监控需要对三层系统(应用层、中间件层、基础层)进行监控。
- **流量控制**。最后是我们的流量控制,负载均衡、服务路由、熔断、降级、限流等和流量相关的调度都会在这里,包括灰度发布之类的功能也在这里。

### 全栈监控
**全栈监控,其实就是三层监控。**
- **基础层:**监控主机和底层资源。比如:CPU、内存、网络吞吐、硬盘 I/O、硬盘使用等。
- **中间层:**就是中间件层的监控。比如:Nginx、Redis、ActiveMQ、Kafka、MySQL、Tomcat 等。应用层:
- **监控应用层的使用**。比如:HTTP 访问的吞吐量、响应时间、返回码、调用链路分析、性能瓶颈,还包括用户端的监控。
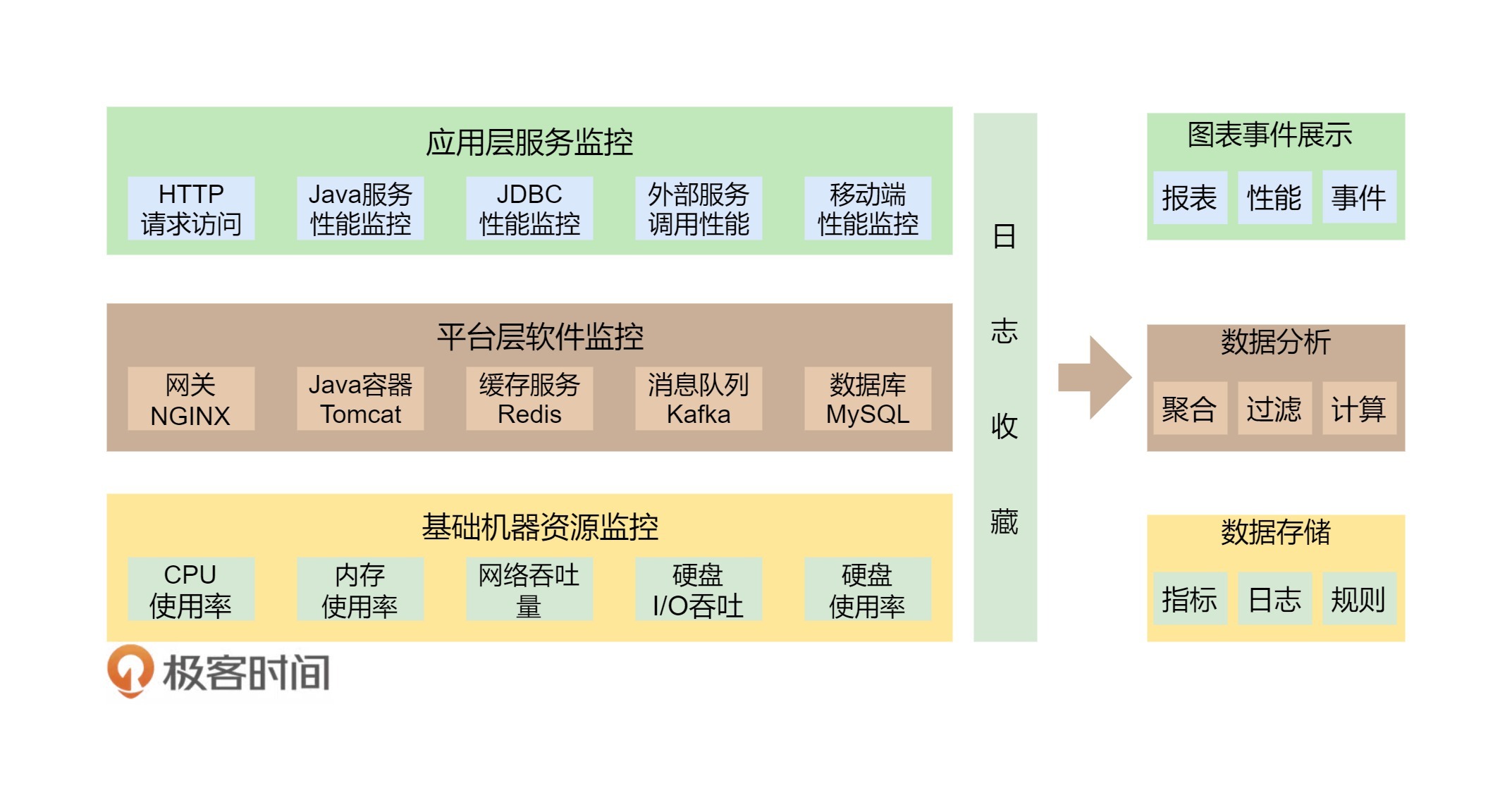
#### 什么才是好的监控系统
**监控系统可能存在的问题:**
1.**监控数据是隔离开来的。**因为公司分工的问题,开发、应用运维、系统运维,各管各的,所以很多公司的监控系统之间都有一道墙,完全串不起来。
**2.监控的数据项太多。**有些公司的运维团队把监控的数据项多作为一个亮点到处讲,比如监控指标达到 5 万多个。老实说,这太丢人了。因为信息太多等于没有信息,抓不住重点的监控才会做成这个样子,完全就是使蛮力的做法。
**好的监控系统有以下几个特征:**
1. **关注于整体应用的 SLA(服务级别协议)。**主要从为用户服务的 API 来监控整个系统。
2. **关联指标聚合。**把有关联的系统及其指标聚合展示。主要是三层系统数据:基础层、平台中间件层和应用层。其中,最重要的是把服务和相关的中间件以及主机关联在一起,服务有可能运行在 Docker 中,也有可能运行在微服务平台上的多个 JVM 中,也有可能运行在 Tomcat 中。总之,无论运行在哪里,我们都需要把服务的具体实例和主机关联在一起,否则,对于一个分布式系统来说,定位问题犹如大海捞针。
3. **快速故障定位。**对于现有的系统来说,故障总是会发生的,而且还会频繁发生。故障发生不可怕,可怕的是故障的恢复时间过长。所以,快速地定位故障就相当关键。快速定位问题需要对整个分布式系统做一个用户请求跟踪的 trace 监控,我们需要监控到所有的请求在分布式系统中的调用链,这个事最好是做成没有侵入性的。
**以下两大主要功能实现**
##### “体检”
- **容量管理。**提供一个全局的系统运行时数据的展示,可以让工程师团队知道是否需要增加机器或者其它资源。
- **性能管理。**可以通过查看大盘,找到系统瓶颈,并有针对性地优化系统和相应代码。
##### “急诊”
- **定位问题**。可以快速地暴露并找到问题的发生点,帮助技术人员诊断问题。
- **性能分析。**当出现非预期的流量提升时,可以快速地找到系统的瓶颈,并帮助开发人员深入代码。
**如何做出一个好的监控系统**
- **服务调用链跟踪。**这个监控系统应该从对外的 API 开始,然后将后台的实际服务给关联起来,然后再进一步将这个服务的依赖服务关联起来,直到最后一个服务(如 MySQL 或 Redis),这样就可以把整个系统的服务全部都串连起来了。这个事情的最佳实践是 Google Dapper 系统,其对应于开源的实现是 Zipkin。对于 Java 类的服务,我们可以使用字节码技术进行字节码注入,做到代码无侵入式。
- **服务调用时长分布。**使用 Zipkin,可以看到一个服务调用链上的时间分布,这样有助于我们知道最耗时的服务是什么。下图是 Zipkin 的服务调用时间分布。
- **服务的 TOP N 视图。**所谓 TOP N 视图就是一个系统请求的排名情况。一般来说,这个排名会有三种排名的方法:a)按调用量排名,b) 按请求最耗时排名,c)按热点排名(一个时间段内的请求次数的响应时间和)。
- **数据库操作关联。**对于 Java 应用,我们可以很方便地通过 JavaAgent 字节码注入技术拿到 JDBC 执行数据库操作的执行时间。对此,我们可以和相关的请求对应起来。
- **服务资源跟踪。**我们的服务可能运行在物理机上,也可能运行在虚拟机里,还可能运行在一个 Docker 的容器里,Docker 容器又运行在物理机或是虚拟机上。我们需要把服务运行的机器节点上的数据(如 CPU、MEM、I/O、DISK、NETWORK)关联起来。
**了这些数据上的关联,我们就可以达到如下的目标。**
1. 当一台机器挂掉是因为 CPU 或 I/O 过高的时候,我们马上可以知道其会影响到哪些对外服务的 API。
2. 当一个服务响应过慢的时候,我们马上能关联出来是否在做 Java GC,或是其所在的计算结点上是否有资源不足的情况,或是依赖的服务是否出现了问题。
3. 当发现一个 SQL 操作过慢的时候,我们能马上知道其会影响哪个对外服务的 API。
4. 当发现一个消息队列拥塞的时候,我们能马上知道其会影响哪些对外服务的 API。
**一旦了解了这些信息,我们就可以做出调度。比如:**
1. 一旦发现某个服务过慢是因为 CPU 使用过多,我们就可以做弹性伸缩。
2. 一旦发现某个服务过慢是因为 MySQL 出现了一个慢查询,我们就无法在应用层上做弹性伸缩,只能做流量限制,或是降级操作了。
**实现效果如下图:**

### 服务调度
**微服务是服务依赖最优解的上限,而服务依赖的下限是千万不要有依赖环。**如果系统架构中有服务依赖环,那么表明你的架构设计是错误的。循环依赖有很多的副作用,最大的问题是这是一种极强的耦合,会导致服务部署相当复杂和难解,而且会导致无穷尽的递归故障和一些你意想不到的问题。
#### 服务状态和生命周期的管理
服务的生命周期通常会有以下几个状态:
- Provision,代表在供应一个新的服务;
- Ready,表示启动成功了;
- Run,表示通过了服务健康检查;
- Update,表示在升级中;
- Rollback,表示在回滚中;
- Scale,表示正在伸缩中(可以有 Scale-in 和 Scale-out 两种);
- Destroy,表示在销毁中;
- Failed,表示失败状态。
这几个状态需要管理好,不然的话,你将不知道这些服务在什么样的状态下。不知道在什么样的状态下,你对整个分布式架构也就无法控制了。
#### 整个架构的版本管理
需要一个架构的 manifest,一个服务清单,这个服务清单定义了所有服务的版本运行环境,其中包括但不限于:
- 服务的软件版本;
- 服务的运行环境——环境变量、CPU、内存、可以运行的节点、文件系统等;
- 服务运行的最大最小实例数。
#### 资源 / 服务调度
服务和资源的调度有点像操作系统。操作系统一方面把用户进程在硬件资源上进行调度,另一方面提供进程间的通信方式,可以让不同的进程在一起协同工作。服务和资源调度的过程,与操作系统调度进程的方式很相似,主要有以下一些关键技术。
- 服务状态的维持和拟合。
- 服务的弹性伸缩和故障迁移。
- 作业和应用调度。
- 作业工作流编排。
- 服务编排。
#### 服务状态的维持
所谓服务状态不是服务中的数据状态,而是服务的运行状态,换句话说就是服务的 Status,而不是 State。也就是上述服务运行时生命周期中的状态——Provision,Ready,Run,Scale,Rollback,Update,Destroy,Failed……服务运行时的状态是非常关键的。
服务运行过程中,状态也是会有变化的,这样的变化有两种。
- 一种是没有预期的变化。比如,服务运行因为故障导致一些服务挂掉,或是别的什么原因出现了服务不健康的状态。而一个好的集群管理控制器应该能够强行维护服务的状态。在健康的实例数变少时,控制器会把不健康的服务给摘除,而又启动几个新的,强行维护健康的服务实例数。
- 另外一种是预期的变化。比如,我们需要发布新版本,需要伸缩,需要回滚。这时,集群管理控制器就应该把集群从现有状态迁移到另一个新的状态。这个过程并不是一蹴而就的,集群控制器需要一步一步地向集群发送若干控制命令。这个过程叫“拟合”——从一个状态拟合到另一个状态,而且要穷尽所有的可能,玩命地不断地拟合,直到达到目的。
#### 服务的弹性伸缩和故障迁移
有了上述的服务状态拟合的基础工作之后,我们就能很容易地管理服务的生命周期了,甚至可以通过底层的支持进行便利的服务弹性伸缩和故障迁移。
对于弹性伸缩,在上面我已经给出了一个服务伸缩所需要的操作步骤。还是比较复杂的,其中涉及到了:
- 底层资源的伸缩;
- 服务的自动化部署;
- 服务的健康检查;
- 服务发现的注册;
- 服务流量的调度。
而对于故障迁移,也就是服务的某个实例出现问题时,我们需要自动地恢复它。对于服务来说,有两种模式,一种是宠物模式,一种是奶牛模式。
- 所谓宠物模式,就是一定要救活,主要是对于 stateful 的服务。
- 而奶牛模式,就是不用救活了,重新生成一个实例。
对于这两种模式,在运行中也是比较复杂的,其中涉及到了:
- 服务的健康监控(这可能需要一个 APM 的监控)。
- 如果是宠物模式,需要:服务的重新启动和服务的监控报警(如果重试恢复不成功,需要人工介入)。
- 如果是奶牛模式,需要:服务的资源申请,服务的自动化部署,服务发现的注册,以及服务的流量调度。
把传统的服务迁移到 Docker 和 Kubernetes 上来,再加上更上层的对服务生命周期的控制系统的调度,我们就可以做到一个完全自动化的运维架构了。
#### 服务工作流和编排
正如上面和操作系统做的类比一样,一个好的操作系统需要能够通过一定的机制把一堆独立工作的进程给协同起来。在分布式的服务调度中,这个工作叫做 **Orchestration**,国内把这个词翻译成**“编排”**。
### 流量与数据调度
关于流量调度,现在很多人都把这个事和服务治理混为一谈了。但是还是应该分开的。
1. 一方面,服务治理是内部系统的事,而流量调度可以是内部的,更是外部接入层的事。
2. 另一方面,服务治理是数据中心的事,而流量调度要做得好,应该是数据中心之外的事,也就是我们常说的边缘计算,是应该在类似于 CDN 上完成的事。
所以,流量调度和服务治理是在不同层面上的,不应该混在一起,所以在系统架构上应该把它们分开。
#### 流量调度的主要功能
对于一个流量调度系统来说,其应该具有的主要功能是:
1. 依据系统运行的情况,自动地进行流量调度,在无需人工干预的情况下,提升整个系统的稳定性;
2. 让系统应对爆品等突发事件时,在弹性计算扩缩容的较长时间窗口内或底层资源消耗殆尽的情况下,保护系统平稳运行。
这还是为了提高系统架构的稳定性和高可用性。
此外,这个流量调度系统还可以完成以下几方面的事情。
- **服务流控。**服务发现、服务路由、服务降级、服务熔断、服务保护等。
- **流量控制。**负载均衡、流量分配、流量控制、异地灾备(多活)等。
- **流量管理。**协议转换、请求校验、数据缓存、数据计算等。
所有的这些都应该是一个 API Gateway 应该做的事。
#### 流量调度的关键技术
一个好的 API Gateway 需要具备以下的关键技术。
- **高性能。**API Gateway 必须使用高性能的技术,所以,也就需要使用高性能的语言。
- **扛流量。**要能扛流量,就需要使用集群技术。集群技术的关键点是在集群内的各个结点中共享数据。这就需要使用像 Paxos、Raft、Gossip 这样的通讯协议。因为 Gateway 需要部署在广域网上,所以还需要集群的分组技术。
- **业务逻辑。**API Gateway 需要有简单的业务逻辑,所以,最好是像 AWS 的 Lambda 服务一样,可以让人注入不同语言的简单业务逻辑。
- **服务化。**一个好的 API Gateway 需要能够通过 Admin API 来不停机地管理配置变更,而不是通过一个.conf 文件来人肉地修改配置。
#### 状态数据调度
对于服务调度来说,最难办的就是有状态的服务了。这里的状态是 State,也就是说,有些服务会保存一些数据,而这些数据是不能丢失的,所以,这些数据是需要随服务一起调度的。
一般来说,我们会通过“转移问题”的方法来让服务变成“无状态的服务”。也就是说,会把这些有状态的东西存储到第三方服务上,比如 Redis、MySQL、ZooKeeper,或是 NFS、Ceph 的文件系统中。
这些“转移问题”的方式把问题转移到了第三方服务上,于是自己的 Java 或 PHP 服务中没有状态,但是 Redis 和 MySQL 上则有了状态。所以,我们可以看到,现在的分布式系统架构中出问题的基本都是这些存储状态的服务。
因为数据存储结点在 Scale 上比较困难,所以成了一个单点的瓶颈。
#### 分布式事务一致性的问题
要解决数据结点的 Scale 问题,也就是让数据服务可以像无状态的服务一样在不同的机器上进行调度,这就会涉及数据的 replication 问题。而数据 replication 则会带来数据一致性的问题,进而对性能带来严重的影响。
要解决数据不丢失的问题,只能通过数据冗余的方法,就算是数据分区,每个区也需要进行数据冗余处理。这就是数据副本。当出现某个节点的数据丢失时,可以从副本读到。数据副本是分布式系统解决数据丢失异常的唯一手段。简单来说:
- 要想让数据有高可用性,就得写多份数据。
- 写多份会引起数据一致性的问题。
- 数据一致性的问题又会引发性能问题
在解决数据副本间的一致性问题时,可以使用以下这些技术方案。
- Master-Slave 方案。
- Master-Master 方案。
- 两阶段和三阶段提交方案。
- Paxos 方案。
**关于分布式的事务处理:**https://coolshell.cn/articles/10910.html
#### 状态数据调总结
- 对于应用层上的分布式事务一致性,只有两阶段提交这样的方式。
- 而底层存储可以解决这个问题的方式是通过一些像 Paxos、Raft 或是 NWR 这样的算法和模型来解决。
- 状态数据调度应该是由分布式存储系统来解决的,这样会更为完美。但是因为数据存储的 Scheme 太多,所以,导致我们有各式各样的分布式存储系统,有文件对象的,有关系型数据库的,有 NoSQL 的,有时序数据的,有搜索数据的,有队列的……
数据调度应该是在 IaaS 层的数据存储解决的问题,而不是在 PaaS 层或者 SaaS 层来解决的。
在 IaaS 层上解决这个问题,一般来说有三种方案,
一种是使用比较廉价的开源产品,如:NFS、Ceph、TiDB、CockroachDB、ElasticSearch、InfluxDB、MySQL Cluster 和 Redis Cluster 之类的;另一种是用云计算厂商的方案。当然,如果不差钱的话,可以使用更为昂贵的商业网络存储方案。
### Pass平台的本质
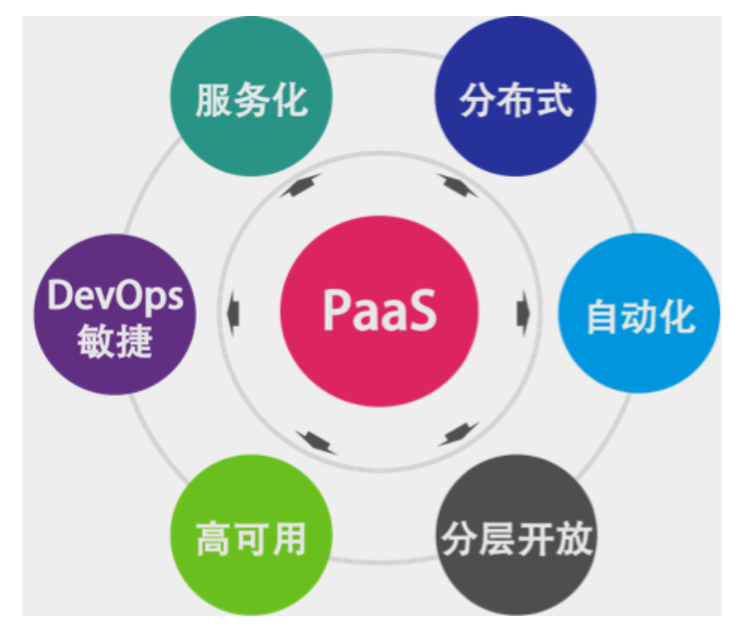
下面这三件事是 PaaS 跟传统中间件最大的差别。
- **服务化是 PaaS 的本质**。软件模块重用,服务治理,对外提供能力是 PaaS 的本质。
- **分布式是 PaaS 的根本特性**。多租户隔离、高可用、服务编排是 PaaS 的基本特性。
- **自动化是 PaaS 的灵魂**。自动化部署安装运维,自动化伸缩调度是 PaaS 的关键。
## PaaS 平台的总体架构
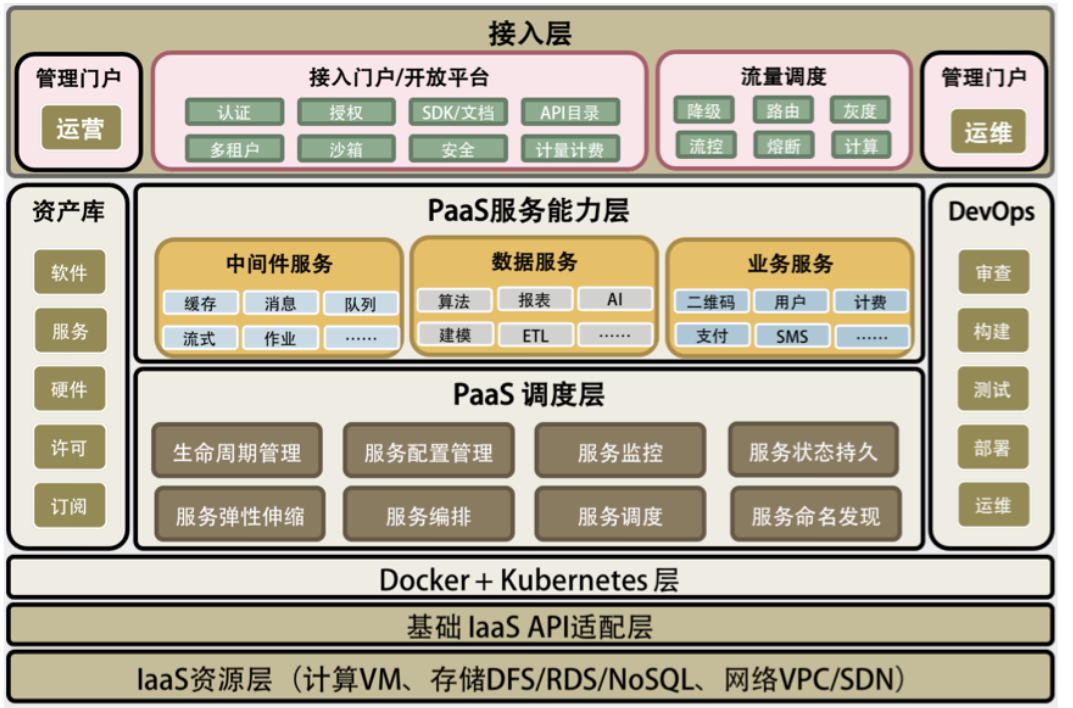
在 Docker+Kubernetes 层之上,我们看到了两个相关的 PaaS 层。一个是 PaaS 调度层,很多人将其称为 iPaaS;另一个是 PaaS 能力层,通常被称为 aPaaS。没有 PaaS 调度层,PaaS 能力层很难被管理和运维,而没有 PaaS 能力层,PaaS 就失去了提供实际能力的业务价值。而本文更多的是在讲 PaaS 调度层上的东西。
一个完整的 PaaS 平台会包括以下几部分。
- PaaS 调度层 – 主要是 PaaS 的自动化和分布式对于高可用高性能的管理。
- PaaS 能力服务层 – 主要是 PaaS 真正提供给用户的服务和能力。
- PaaS 的流量调度 – 主要是与流量调度相关的东西,包括对高并发的管理。
- PaaS 的运营管理 – 软件资源库、软件接入、认证和开放平台门户。
- PaaS 的运维管理 – 主要是 DevOps 相关的东西。
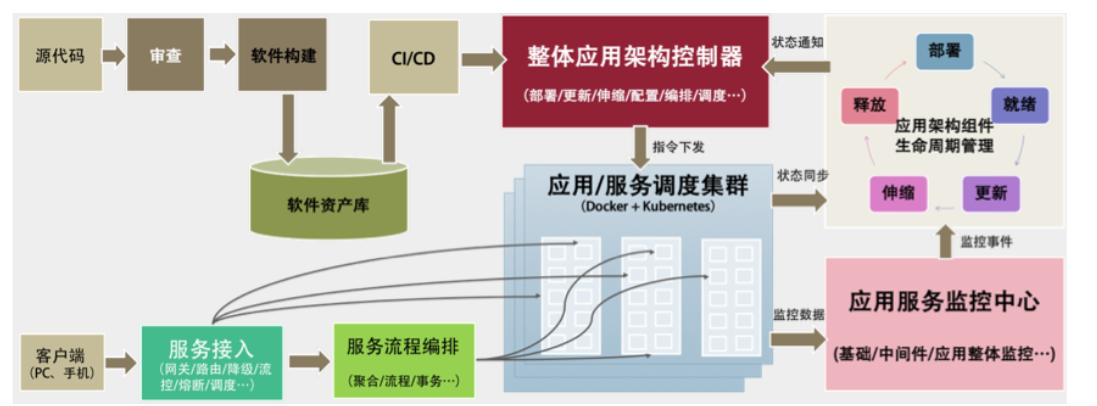
## PaaS 平台的生产和运维
### 总结
传统的单体架构系统容量显然是有上限的。同时,为了应对有计划和无计划的下线时间,系统的可用性也是有其极限的。分布式系统为以上两个问题提供了解决方案,并且还附带有其他优势。但是,要同时解决这两个问题决非易事。为了构建分布式系统,我们面临的主要问题如下。
- 分布式系统的硬件故障发生率更高,故障发生是常态,需要尽可能地将运维流程自动化。
- 需要良好地设计服务,避免某服务的单点故障对依赖它的其他服务造成大面积影响。
- 为了容量的可伸缩性,服务的拆分、自治和无状态变得更加重要,可能需要对老的软件逻辑做大的修改。
- 老的服务可能是异构的,此时需要让它们使用标准的协议,以便可以被调度、编排,且互相之间可以通信。
- 服务软件故障的处理也变得复杂,需要优化的流程,以加快故障的恢复。
- 为了管理各个服务的容量,让分布式系统发挥出最佳性能,需要有流量调度技术。
- 分布式存储会让事务处理变得复杂;在事务遇到故障无法被自动恢复的情况下,手动恢复流程也会变得复杂。
- 测试和查错的复杂度增大。
- 系统的吞吐量会变大,但响应时间会变长。
为了解决这些问题,我们深入了解了以下这些解决方案。
- 需要有完善的监控系统,以便对服务运行状态有全面的了解。
- 设计服务时要分析其依赖链;当非关键服务故障时,其他服务要自动降级功能,避免调用该服务。
- 重构老的软件,使其能被服务化;可以参考 SOA 和微服务的设计方式,目标是微服务化;使用 Docker 和 Kubernetes 来调度服务。
- 为老的服务编写接口逻辑来使用标准协议,或在必要时重构老的服务以使得它们有这些功能。
- 自动构建服务的依赖地图,并引入好的处理流程,让团队能以最快速度定位和恢复故障。
- 使用一个 API Gateway,它具备服务流向控制、流量控制和管理的功能。
- 事务处理建议在存储层实现;根据业务需求,或者降级使用更简单、吞吐量更大的最终一致性方案,或者通过二阶段提交、Paxos、Raft、NWR 等方案之一,使用吞吐量小的强一致性方案。
- 通过更真实地模拟生产环境,乃至在生产环境中做灰度发布,从而增加测试强度;同时做充分的单元测试和集成测试以发现和消除缺陷;最后,在服务故障发生时,相关的多个团队同时上线自查服务状态,以最快地定位故障原因。
- 通过异步调用来减少对短响应时间的依赖;对关键服务提供专属硬件资源,并优化软件逻辑以缩短响应时间。
### 基础理论
## [CAP 定理](https://en.wikipedia.org/wiki/CAP_theorem)
CAP 定理是分布式系统设计中最基础,也是最为关键的理论。它指出,分布式数据存储不可能同时满足以下三个条件。
- **一致性(Consistency)**:每次读取要么获得最近写入的数据,要么获得一个错误。
- **可用性(Availability)**:每次请求都能获得一个(非错误)响应,但不保证返回的是最新写入的数据。
- **分区容忍(Partition tolerance)**:尽管任意数量的消息被节点间的网络丢失(或延迟),系统仍继续运行。
也就是说,CAP 定理表明,在存在网络分区的情况下,一致性和可用性必须二选一。而在没有发生网络故障时,即分布式系统正常运行时,一致性和可用性是可以同时被满足的。这里需要注意的是,CAP 定理中的一致性与 ACID 数据库事务中的一致性截然不同。
掌握 CAP 定理,尤其是能够正确理解 C、A、P 的含义,对于系统架构来说非常重要。因为对于分布式系统来说,网络故障在所难免,如何在出现网络故障的时候,维持系统按照正常的行为逻辑运行就显得尤为重要。你可以结合实际的业务场景和具体需求,来进行权衡。
例如,对于大多数互联网应用来说(如门户网站),因为机器数量庞大,部署节点分散,网络故障是常态,可用性是必须要保证的,所以只有舍弃一致性来保证服务的 AP。而对于银行等,需要确保一致性的场景,通常会权衡 CA 和 CP 模型,CA 模型网络故障时完全不可用,CP 模型具备部分可用性。
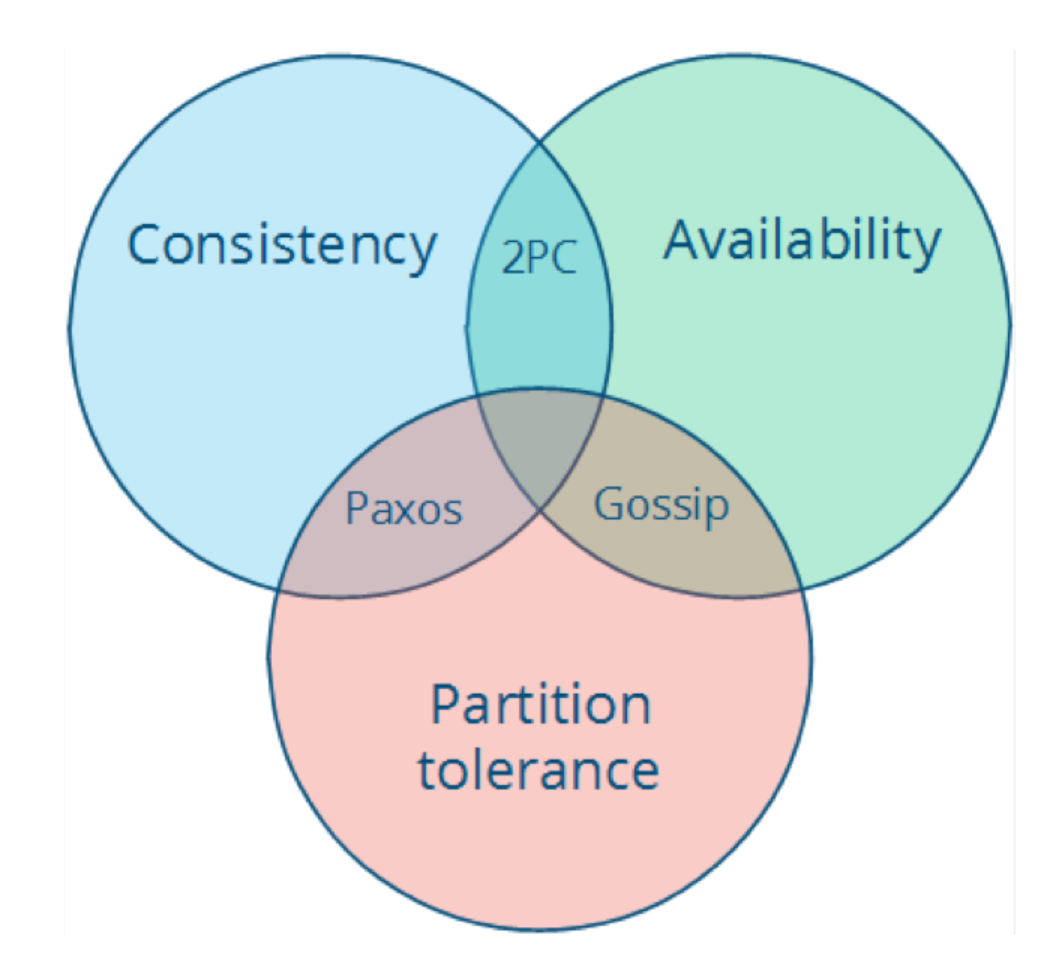
- CA (consistency + availability),这样的系统关注一致性和可用性,它需要非常严格的全体一致的协议,比如“两阶段提交”(2PC)。CA 系统不能容忍网络错误或节点错误,一旦出现这样的问题,整个系统就会拒绝写请求,因为它并不知道对面的那个结点是否挂掉了,还是只是网络问题。唯一安全的做法就是把自己变成只读的。
- CP (consistency + partition tolerance),这样的系统关注一致性和分区容忍性。它关注的是系统里大多数人的一致性协议,比如:Paxos 算法(Quorum 类的算法)。这样的系统只需要保证大多数结点数据一致,而少数的结点会在没有同步到最新版本的数据时变成不可用的状态。这样能够提供一部分的可用性。
- AP (availability + partition tolerance),这样的系统关心可用性和分区容忍性。因此,这样的系统不能达成一致性,需要给出数据冲突,给出数据冲突就需要维护数据版本。Dynamo 就是这样的系统。
#### Paxos 算法
Paxos 算法,是莱斯利·兰伯特(Lesile Lamport)于 1990 年提出来的一种基于消息传递且具有高度容错特性的一致性算法。但是这个算法太过于晦涩,所以,一直以来都属于理论上的论文性质的东西。
#### Raft 算法
因为 Paxos 算法太过于晦涩,而且在实际的实现上有太多的坑,并不太容易写对。所以,有人搞出了另外一个一致性的算法,叫 Raft。其原始论文是[ In search of an Understandable Consensus Algorithm (Extended Version) ](https://raft.github.io/raft.pdf)寻找一种易于理解的 Raft 算法。这篇论文的译文在 InfoQ 上《[Raft 一致性算法论文译文](http://www.infoq.com/cn/articles/raft-paper)》
Raft 算法和 Paxos 的性能和功能是一样的,但是它和 Paxos 算法的结构不一样,这使 Raft 算法更容易理解并且更容易实现。那么 Raft 是怎样做到的呢?
Raft 把这个一致性的算法分解成了几个部分,一个是领导选举(Leader Selection),一个是日志复制(Log Replication),一个是安全性(Safety),还有一个是成员变化(Membership Changes)。对于一般人来说,Raft 协议比 Paxos 的学习曲线更低,也更平滑。
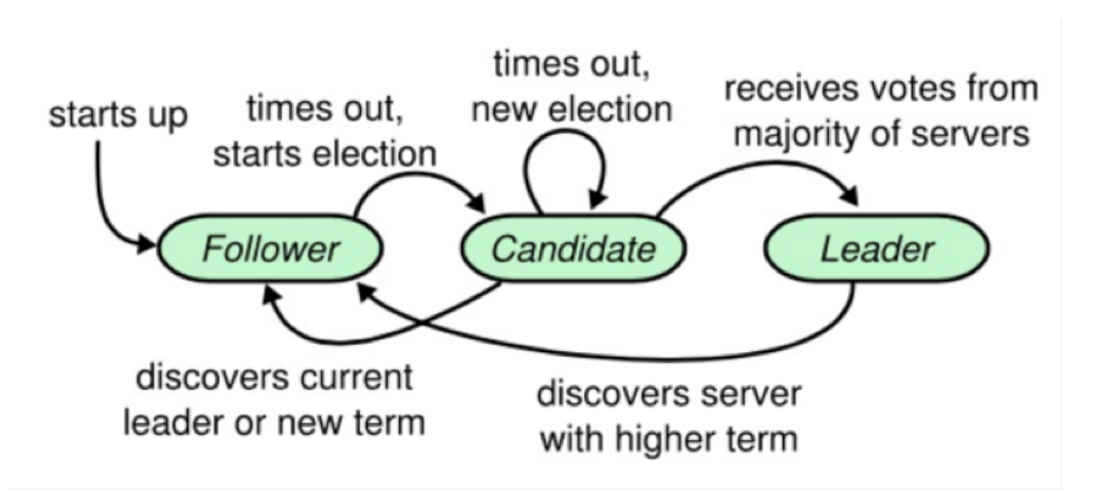
Raft 协议中有一个状态机,每个结点会有三个状态,分别是 Leader、Candidate 和 Follower。Follower 只响应其他服务器的请求,如果没有收到任何信息,它就会成为一个 Candidate,并开始进行选举。收到大多数人同意选票的人会成为新的 Leader。
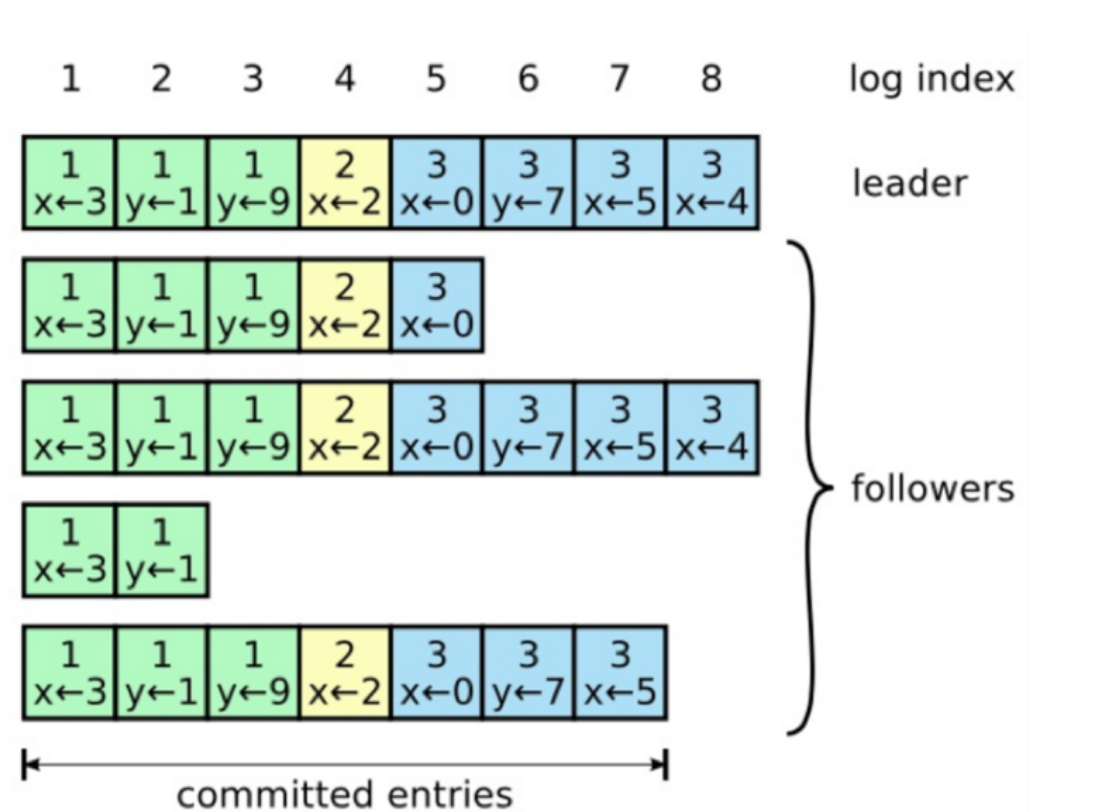
一旦选举出了一个 Leader,它就开始负责服务客户端的请求。每个客户端的请求都包含一个要被复制状态机执行的指令。Leader 首先要把这个指令追加到 log 中形成一个新的 entry,然后通过 AppendEntries RPC 并行地把该 entry 发给其他服务器(server)。如果其他服务器没发现问题,复制成功后会给 Leader 一个表示成功的 ACK。
Leader 收到大多数 ACK 后应用该日志,返回客户端执行结果。如果 Follower 崩溃 (crash)或者丢包,Leader 会不断重试 AppendEntries RPC。
几个不错的 Raft 算法的动画演示。
- [Raft – The Secret Lives of Data](http://thesecretlivesofdata.com/raft/)
- [Raft Consensus Algorithm](https://raft.github.io/)
- [Raft Distributed Consensus Algorithm Visualization](http://kanaka.github.io/raft.js/)
#### 逻辑钟和向量钟
后面,业内又搞出来一些工程上的东西,比如 Amazon 的 DynamoDB,其论文[Dynamo: Amazon’s Highly Available Key Value Store](http://bnrg.eecs.berkeley.edu/~randy/Courses/CS294.F07/Dynamo.pdf) 的影响力也很大。这篇论文中讲述了 Amazon 的 DynamoDB 是如何满足系统的高可用、高扩展和高可靠要求的,其中还展示了系统架构是如何做到数据分布以及数据一致性的。
GFS 采用的是查表式的数据分布,而 DynamoDB 采用的是计算式的,也是一个改进版的通过虚拟结点减少增加结点带来数据迁移的一致性哈希。另外,这篇论文中还讲述了一个 NRW 模式用于让用户可以灵活地在 CAP 系统中选取其中两项,这使用到了 Vector Clock——向量时钟来检测相应的数据冲突。最后还介绍了使用 Handoff 的机制对可用性的提升。
这篇文章中有几个关键的概念,一个是 Vector Clock,另一个是 Gossip 协议。
提到向量时钟就需要提一下逻辑时钟。所谓逻辑时间,也就是在分布系统中为了解决消息有序的问题,由于在不同的机器上有不同的本地时间,这些本地时间的同步很难搞,会导致消息乱序。
于是 Paxos 算法的发明人兰伯特(Lamport)搞了个向量时钟,每个系统维护一个本地的计数器,这就是所谓的逻辑时钟。每执行一个事件(例如向网络发送消息,或是交付到应用层)都对这个计数器做加 1 操作。当跨系统的时候,在消息体上附着本地计算器,当接收端收到消息时,更新自己的计数器(取对端传来的计数器和自己当成计数器的最大值),也就是调整自己的时钟。
逻辑时钟可以保证,如果事件 A 先于事件 B,那么事件 A 的时钟一定小于事件 B 的时钟,但是返过来则无法保证,因为返过来没有因果关系。所以,向量时钟解释了因果关系。向量时钟维护了数据更新的一组版本号(版本号其实就是使用逻辑时钟)。
假如一个数据需要存在三个结点上 A、B、C。那么向量维度就是 3,在初始化的时候,所有结点对于这个数据的向量版本是 [A:0, B:0, C:0]。当有数据更新时,比如从 A 结点更新,那么,数据的向量版本变成 [A:1, B:0, C:0],然后向其他结点复制这个版本,其在语义上表示为我当前的数据是由 A 结果更新的,而在逻辑上则可以让分布式系统中的数据更新的顺序找到相关的因果关系。
这其中的逻辑关系,你可以看一下[ 马萨诸塞大学课程 Distributed Operating System ](http://lass.cs.umass.edu/~shenoy/courses/spring05/lectures.html)中第 10 节[ Clock Synchronization ](http://lass.cs.umass.edu/~shenoy/courses/spring05/lectures/Lec10.pdf)这篇讲议。关于 Vector Clock,你可以看一下[ Why Vector Clocks are Easy](http://basho.com/posts/technical/why-vector-clocks-are-easy/)和[Why Vector Clocks are Hard](http://basho.com/posts/technical/why-vector-clocks-are-hard/) 这两篇文章。
#### Gossip 协议
另外,DynamoDB 中使用到了 Gossip 协议来做数据同步,这个协议的原始论文是 [Efficient Reconciliation and Flow Control for Anti-Entropy Protocols](https://www.cs.cornell.edu/home/rvr/papers/flowgossip.pdf)。Gossip 算法也是 Cassandra 使用的数据复制协议。这个协议就像八卦和谣言传播一样,可以 “一传十、十传百”传播开来。但是这个协议看似简单,细节上却非常麻烦。
根据这篇论文,节点之间存在三种通信方式。
- push 方式。A 节点将数据 (key,value,version) 及对应的版本号推送给 B 节点,B 节点更新 A 中比自己新的数据。
- pull 方式。A 仅将数据 key,version 推送给 B,B 将本地比 A 新的数据 (key,value,version) 推送给 A,A 更新本地。
- push/pull 方式。与 pull 类似,只是多了一步,A 再将本地比 B 新的数据推送给 B,B 更新本地。
如果把两个节点数据同步一次定义为一个周期,那么在一个周期内,push 需通信 1 次,pull 需 2 次,push/pull 则需 3 次。从效果上来讲,push/pull 最好,理论上一个周期内可以使两个节点完全一致。直观感觉上,也是 push/pull 的收敛速度最快。
另外,每个节点上的又需要一个协调机制,也就是如何交换数据能达到最快的一致性——消除节点的不一致性。上面所讲的 push、pull 等是通信方式,协调是在通信方式下的数据交换机制。
关于 Gossip 的一些图示化的东西,可以看一下动画[gossip visualization](https://rrmoelker.github.io/gossip-visualization/)。
#### 分布式数据库方面
数据库方面的一些论文。
一篇是 AWS Aurora 的论文 [Amazon Aurora: Design Considerations for High Throughput Cloud –Native Relation Databases](http://www.allthingsdistributed.com/files/p1041-verbitski.pdf)。
Aurora 是 AWS 将 MySQL 的计算和存储分离后,计算节点 scale up,存储节点 scale out。并把其 redo log 独立设计成一个存储服务,把分布式的数据方面的东西全部甩给了底层存储系统。从而提高了整体的吞吐量和水平的扩展能力。
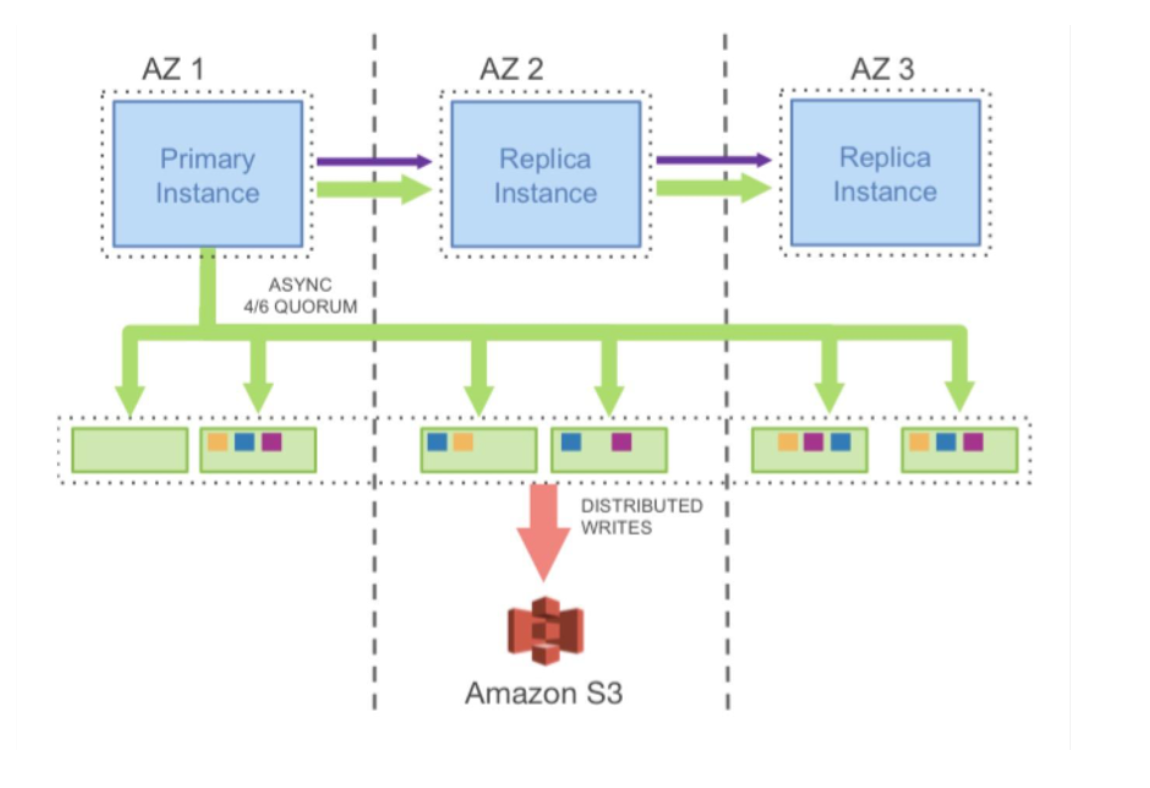
Aurora 要写 6 份拷贝,但是其只需要把一个 Quorum 中的日志写成功就可以了。如下所示。可以看到,将存储服务做成一个跨数据中心的服务,提高数据库容灾,降低性能影响。
对于存储服务的设计,核心的原理就是 latency 一定要低,毕竟写 6 个 copy 是一件开销很大的事。所以,基本上来说,Aurora 用的是异步模型,然后拼命地做并行处理,其中用到的也是 Gossip 协议。如下所示。
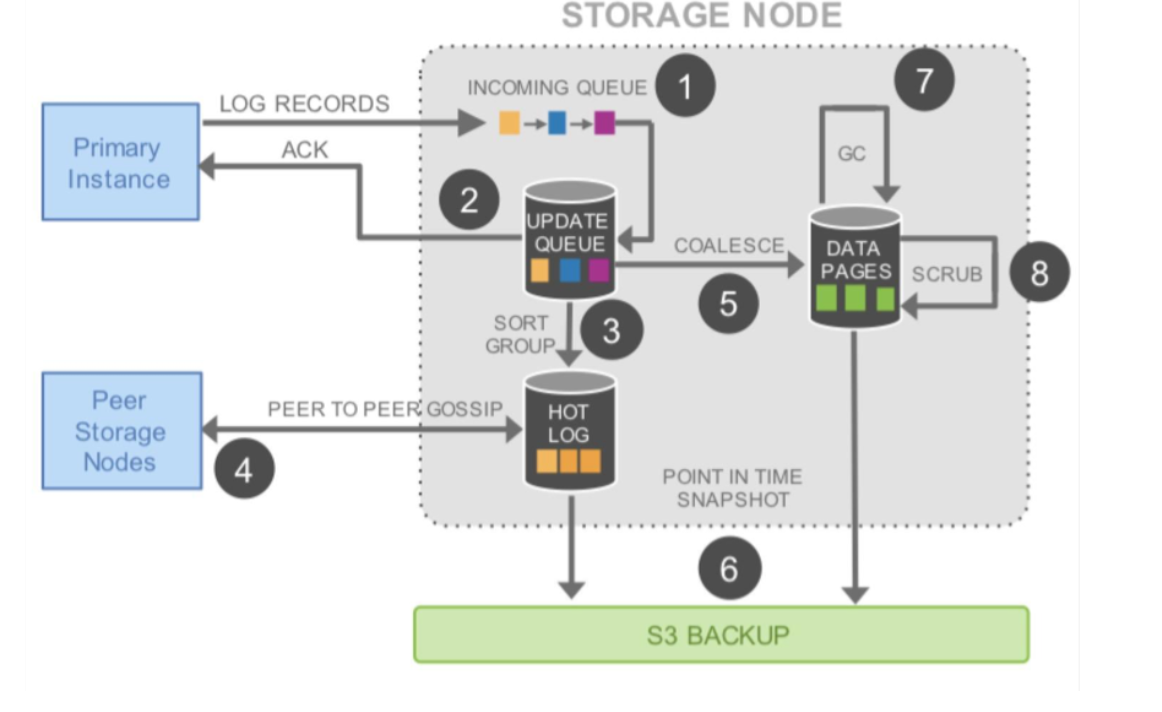
在上面这个图中,我们可以看到,完成前两步,就可以 ACK 回调用方。也就是说,只要数据在本地落地了,就可以返回成功了。然后,对于六个副本,这个 log 会同时发送到 6 个存储结点,只需要有大于 4 个成功 ACK,就算写成功了。第 4 步我们可以看到用的是 Gossip 协议。然后,第 5 步产生 cache 页,便于查询。第 6 步在 S3 做 Snapshot,类似于 Checkpoint。
### 经典资料
- Distributed systems theory for the distributed systems engineer
- FLP Impossibility Result
- An introduction to distributed systems
- Distributed Systems for fun and profit
- Distributed Systems: Principles and Paradigms
- Scalable Web Architecture and Distributed Systems
- Principles of Distributed Systems
- Making reliable distributed systems in the presence of software errors
- Designing Data Intensive Applications

**存在的问题:**
- 架构设计变得复杂(尤其是其中的分布式事务)。
- 部署单个服务会比较快,但是如果一次部署需要多个服务,流程会变得复杂。
- 系统的吞吐量会变大,但是响应时间会变长。
- 运维复杂度会因为服务变多而变得很复杂。
- 架构复杂导致学习曲线变大。
- 测试和查错的复杂度增大。
- 技术多元化,这会带来维护和运维的复杂度。
- 管理分布式系统中的服务和调度变得困难和复杂。
## 分布式系统的目的以及相关技术
**构建分布式系统的目的是增加系统容量,提高系统的可用性,转换成技术方面,也就是完成下面两件事。**
- **大流量处理。**通过集群技术把大规模并发请求的负载分散到不同的机器上。
- **关键业务保护。**提高后台服务的可用性,把故障隔离起来阻止多米诺骨牌效应(雪崩效应)。如果流量过大,需要对业务降级,以保护关键业务流转。
### 提高架构的性能

- **缓存系统。**加入缓存系统,可以有效地提高系统的访问能力。从前端的浏览器,到网络,再到后端的服务,底层的数据库、文件系统、硬盘和 CPU,全都有缓存,这是提高快速访问能力最有效的手段。对于分布式系统下的缓存系统,需要的是一个缓存集群。这其中需要一个 Proxy 来做缓存的分片和路由。
- **负载均衡系统。**负载均衡系统是水平扩展的关键技术,它可以使用多台机器来共同分担一部分流量请求。
- **异步调用。**异步系统主要通过消息队列来对请求做排队处理,这样可以把前端的请求的峰值给“削平”了,而后端通过自己能够处理的速度来处理请求。这样可以增加系统的吞吐量,但是实时性就差很多了。同时,还会引入消息丢失的问题,所以要对消息做持久化,这会造成“有状态”的结点,从而增加了服务调度的难度。
- **数据分区和数据镜像。数据分区**是把数据按一定的方式分成多个区(比如通过地理位置),不同的数据区来分担不同区的流量。这需要一个数据路由的中间件,会导致跨库的 Join 和跨库的事务非常复杂。而**数据镜像**是把一个数据库镜像成多份一样的数据,这样就不需要数据路由的中间件了。你可以在任意结点上进行读写,内部会自行同步数据。然而,数据镜像中最大的问题就是数据的一致性问题。
### 提高架构的稳定性

- **服务拆分。**服务拆分主要有两个目的:一是为了隔离故障,二是为了重用服务模块。但服务拆分完之后,会引入服务调用间的依赖问题。
- **服务冗余。**服务冗余是为了去除单点故障,并可以支持服务的弹性伸缩,以及故障迁移。然而,对于一些有状态的服务来说,冗余这些有状态的服务带来了更高的复杂性。其中一个是弹性伸缩时,需要考虑数据的复制或是重新分片,迁移的时候还要迁移数据到其它机器上。
- **限流降级。**当系统实在扛不住压力时,只能通过限流或者功能降级的方式来停掉一部分服务,或是拒绝一部分用户,以确保整个架构不会挂掉。这些技术属于保护措施。
- **高可用架构。**通常来说高可用架构是从冗余架构的角度来保障可用性。比如,多租户隔离,灾备多活,或是数据可以在其中复制保持一致性的集群。总之,就是为了不出单点故障。
- **高可用运维。**高可用运维指的是 DevOps 中的 CI/CD(持续集成 / 持续部署)。一个良好的运维应该是一条很流畅的软件发布管线,其中做了足够的自动化测试,还可以做相应的灰度发布,以及对线上系统的自动化控制。这样,可以做到“计划内”或是“非计划内”的宕机事件的时长最短。
### 分布式系统的关键技术
- **服务治理。**服务拆分、服务调用、服务发现、服务依赖、服务的关键度定义……服务治理的最大意义是需要把服务间的依赖关系、服务调用链,以及关键的服务给梳理出来,并对这些服务进行性能和可用性方面的管理。
- **架构软件管理。**服务之间有依赖,而且有兼容性问题,所以,整体服务所形成的架构需要有架构版本管理、整体架构的生命周期管理,以及对服务的编排、聚合、事务处理等服务调度功能。
- **DevOps。**分布式系统可以更为快速地更新服务,但是对于服务的测试和部署都会是挑战。所以,还需要 DevOps 的全流程,其中包括环境构建、持续集成、持续部署等。
- **自动化运维。**有了 DevOps 后,我们就可以对服务进行自动伸缩、故障迁移、配置管理、状态管理等一系列的自动化运维技术了。
- **资源调度管理。**应用层的自动化运维需要基础层的调度支持,也就是云计算 IaaS 层的计算、存储、网络等资源调度、隔离和管理。
- **整体架构监控。**如果没有一个好的监控系统,那么自动化运维和资源调度管理只可能成为一个泡影,因为监控系统是你的眼睛。没有眼睛,没有数据,就无法进行高效运维。所以说,监控是非常重要的部分。这里的监控需要对三层系统(应用层、中间件层、基础层)进行监控。
- **流量控制**。最后是我们的流量控制,负载均衡、服务路由、熔断、降级、限流等和流量相关的调度都会在这里,包括灰度发布之类的功能也在这里。

### 全栈监控
**全栈监控,其实就是三层监控。**
- **基础层:**监控主机和底层资源。比如:CPU、内存、网络吞吐、硬盘 I/O、硬盘使用等。
- **中间层:**就是中间件层的监控。比如:Nginx、Redis、ActiveMQ、Kafka、MySQL、Tomcat 等。应用层:
- **监控应用层的使用**。比如:HTTP 访问的吞吐量、响应时间、返回码、调用链路分析、性能瓶颈,还包括用户端的监控。

#### 什么才是好的监控系统
**监控系统可能存在的问题:**
1.**监控数据是隔离开来的。**因为公司分工的问题,开发、应用运维、系统运维,各管各的,所以很多公司的监控系统之间都有一道墙,完全串不起来。
**2.监控的数据项太多。**有些公司的运维团队把监控的数据项多作为一个亮点到处讲,比如监控指标达到 5 万多个。老实说,这太丢人了。因为信息太多等于没有信息,抓不住重点的监控才会做成这个样子,完全就是使蛮力的做法。
**好的监控系统有以下几个特征:**
1. **关注于整体应用的 SLA(服务级别协议)。**主要从为用户服务的 API 来监控整个系统。
2. **关联指标聚合。**把有关联的系统及其指标聚合展示。主要是三层系统数据:基础层、平台中间件层和应用层。其中,最重要的是把服务和相关的中间件以及主机关联在一起,服务有可能运行在 Docker 中,也有可能运行在微服务平台上的多个 JVM 中,也有可能运行在 Tomcat 中。总之,无论运行在哪里,我们都需要把服务的具体实例和主机关联在一起,否则,对于一个分布式系统来说,定位问题犹如大海捞针。
3. **快速故障定位。**对于现有的系统来说,故障总是会发生的,而且还会频繁发生。故障发生不可怕,可怕的是故障的恢复时间过长。所以,快速地定位故障就相当关键。快速定位问题需要对整个分布式系统做一个用户请求跟踪的 trace 监控,我们需要监控到所有的请求在分布式系统中的调用链,这个事最好是做成没有侵入性的。
**以下两大主要功能实现**
##### “体检”
- **容量管理。**提供一个全局的系统运行时数据的展示,可以让工程师团队知道是否需要增加机器或者其它资源。
- **性能管理。**可以通过查看大盘,找到系统瓶颈,并有针对性地优化系统和相应代码。
##### “急诊”
- **定位问题**。可以快速地暴露并找到问题的发生点,帮助技术人员诊断问题。
- **性能分析。**当出现非预期的流量提升时,可以快速地找到系统的瓶颈,并帮助开发人员深入代码。
**如何做出一个好的监控系统**
- **服务调用链跟踪。**这个监控系统应该从对外的 API 开始,然后将后台的实际服务给关联起来,然后再进一步将这个服务的依赖服务关联起来,直到最后一个服务(如 MySQL 或 Redis),这样就可以把整个系统的服务全部都串连起来了。这个事情的最佳实践是 Google Dapper 系统,其对应于开源的实现是 Zipkin。对于 Java 类的服务,我们可以使用字节码技术进行字节码注入,做到代码无侵入式。
- **服务调用时长分布。**使用 Zipkin,可以看到一个服务调用链上的时间分布,这样有助于我们知道最耗时的服务是什么。下图是 Zipkin 的服务调用时间分布。
- **服务的 TOP N 视图。**所谓 TOP N 视图就是一个系统请求的排名情况。一般来说,这个排名会有三种排名的方法:a)按调用量排名,b) 按请求最耗时排名,c)按热点排名(一个时间段内的请求次数的响应时间和)。
- **数据库操作关联。**对于 Java 应用,我们可以很方便地通过 JavaAgent 字节码注入技术拿到 JDBC 执行数据库操作的执行时间。对此,我们可以和相关的请求对应起来。
- **服务资源跟踪。**我们的服务可能运行在物理机上,也可能运行在虚拟机里,还可能运行在一个 Docker 的容器里,Docker 容器又运行在物理机或是虚拟机上。我们需要把服务运行的机器节点上的数据(如 CPU、MEM、I/O、DISK、NETWORK)关联起来。
**了这些数据上的关联,我们就可以达到如下的目标。**
1. 当一台机器挂掉是因为 CPU 或 I/O 过高的时候,我们马上可以知道其会影响到哪些对外服务的 API。
2. 当一个服务响应过慢的时候,我们马上能关联出来是否在做 Java GC,或是其所在的计算结点上是否有资源不足的情况,或是依赖的服务是否出现了问题。
3. 当发现一个 SQL 操作过慢的时候,我们能马上知道其会影响哪个对外服务的 API。
4. 当发现一个消息队列拥塞的时候,我们能马上知道其会影响哪些对外服务的 API。
**一旦了解了这些信息,我们就可以做出调度。比如:**
1. 一旦发现某个服务过慢是因为 CPU 使用过多,我们就可以做弹性伸缩。
2. 一旦发现某个服务过慢是因为 MySQL 出现了一个慢查询,我们就无法在应用层上做弹性伸缩,只能做流量限制,或是降级操作了。
**实现效果如下图:**

### 服务调度
**微服务是服务依赖最优解的上限,而服务依赖的下限是千万不要有依赖环。**如果系统架构中有服务依赖环,那么表明你的架构设计是错误的。循环依赖有很多的副作用,最大的问题是这是一种极强的耦合,会导致服务部署相当复杂和难解,而且会导致无穷尽的递归故障和一些你意想不到的问题。
#### 服务状态和生命周期的管理
服务的生命周期通常会有以下几个状态:
- Provision,代表在供应一个新的服务;
- Ready,表示启动成功了;
- Run,表示通过了服务健康检查;
- Update,表示在升级中;
- Rollback,表示在回滚中;
- Scale,表示正在伸缩中(可以有 Scale-in 和 Scale-out 两种);
- Destroy,表示在销毁中;
- Failed,表示失败状态。
这几个状态需要管理好,不然的话,你将不知道这些服务在什么样的状态下。不知道在什么样的状态下,你对整个分布式架构也就无法控制了。
#### 整个架构的版本管理
需要一个架构的 manifest,一个服务清单,这个服务清单定义了所有服务的版本运行环境,其中包括但不限于:
- 服务的软件版本;
- 服务的运行环境——环境变量、CPU、内存、可以运行的节点、文件系统等;
- 服务运行的最大最小实例数。
#### 资源 / 服务调度
服务和资源的调度有点像操作系统。操作系统一方面把用户进程在硬件资源上进行调度,另一方面提供进程间的通信方式,可以让不同的进程在一起协同工作。服务和资源调度的过程,与操作系统调度进程的方式很相似,主要有以下一些关键技术。
- 服务状态的维持和拟合。
- 服务的弹性伸缩和故障迁移。
- 作业和应用调度。
- 作业工作流编排。
- 服务编排。
#### 服务状态的维持
所谓服务状态不是服务中的数据状态,而是服务的运行状态,换句话说就是服务的 Status,而不是 State。也就是上述服务运行时生命周期中的状态——Provision,Ready,Run,Scale,Rollback,Update,Destroy,Failed……服务运行时的状态是非常关键的。
服务运行过程中,状态也是会有变化的,这样的变化有两种。
- 一种是没有预期的变化。比如,服务运行因为故障导致一些服务挂掉,或是别的什么原因出现了服务不健康的状态。而一个好的集群管理控制器应该能够强行维护服务的状态。在健康的实例数变少时,控制器会把不健康的服务给摘除,而又启动几个新的,强行维护健康的服务实例数。
- 另外一种是预期的变化。比如,我们需要发布新版本,需要伸缩,需要回滚。这时,集群管理控制器就应该把集群从现有状态迁移到另一个新的状态。这个过程并不是一蹴而就的,集群控制器需要一步一步地向集群发送若干控制命令。这个过程叫“拟合”——从一个状态拟合到另一个状态,而且要穷尽所有的可能,玩命地不断地拟合,直到达到目的。
#### 服务的弹性伸缩和故障迁移
有了上述的服务状态拟合的基础工作之后,我们就能很容易地管理服务的生命周期了,甚至可以通过底层的支持进行便利的服务弹性伸缩和故障迁移。
对于弹性伸缩,在上面我已经给出了一个服务伸缩所需要的操作步骤。还是比较复杂的,其中涉及到了:
- 底层资源的伸缩;
- 服务的自动化部署;
- 服务的健康检查;
- 服务发现的注册;
- 服务流量的调度。
而对于故障迁移,也就是服务的某个实例出现问题时,我们需要自动地恢复它。对于服务来说,有两种模式,一种是宠物模式,一种是奶牛模式。
- 所谓宠物模式,就是一定要救活,主要是对于 stateful 的服务。
- 而奶牛模式,就是不用救活了,重新生成一个实例。
对于这两种模式,在运行中也是比较复杂的,其中涉及到了:
- 服务的健康监控(这可能需要一个 APM 的监控)。
- 如果是宠物模式,需要:服务的重新启动和服务的监控报警(如果重试恢复不成功,需要人工介入)。
- 如果是奶牛模式,需要:服务的资源申请,服务的自动化部署,服务发现的注册,以及服务的流量调度。
把传统的服务迁移到 Docker 和 Kubernetes 上来,再加上更上层的对服务生命周期的控制系统的调度,我们就可以做到一个完全自动化的运维架构了。
#### 服务工作流和编排
正如上面和操作系统做的类比一样,一个好的操作系统需要能够通过一定的机制把一堆独立工作的进程给协同起来。在分布式的服务调度中,这个工作叫做 **Orchestration**,国内把这个词翻译成**“编排”**。
### 流量与数据调度
关于流量调度,现在很多人都把这个事和服务治理混为一谈了。但是还是应该分开的。
1. 一方面,服务治理是内部系统的事,而流量调度可以是内部的,更是外部接入层的事。
2. 另一方面,服务治理是数据中心的事,而流量调度要做得好,应该是数据中心之外的事,也就是我们常说的边缘计算,是应该在类似于 CDN 上完成的事。
所以,流量调度和服务治理是在不同层面上的,不应该混在一起,所以在系统架构上应该把它们分开。
#### 流量调度的主要功能
对于一个流量调度系统来说,其应该具有的主要功能是:
1. 依据系统运行的情况,自动地进行流量调度,在无需人工干预的情况下,提升整个系统的稳定性;
2. 让系统应对爆品等突发事件时,在弹性计算扩缩容的较长时间窗口内或底层资源消耗殆尽的情况下,保护系统平稳运行。
这还是为了提高系统架构的稳定性和高可用性。
此外,这个流量调度系统还可以完成以下几方面的事情。
- **服务流控。**服务发现、服务路由、服务降级、服务熔断、服务保护等。
- **流量控制。**负载均衡、流量分配、流量控制、异地灾备(多活)等。
- **流量管理。**协议转换、请求校验、数据缓存、数据计算等。
所有的这些都应该是一个 API Gateway 应该做的事。
#### 流量调度的关键技术
一个好的 API Gateway 需要具备以下的关键技术。
- **高性能。**API Gateway 必须使用高性能的技术,所以,也就需要使用高性能的语言。
- **扛流量。**要能扛流量,就需要使用集群技术。集群技术的关键点是在集群内的各个结点中共享数据。这就需要使用像 Paxos、Raft、Gossip 这样的通讯协议。因为 Gateway 需要部署在广域网上,所以还需要集群的分组技术。
- **业务逻辑。**API Gateway 需要有简单的业务逻辑,所以,最好是像 AWS 的 Lambda 服务一样,可以让人注入不同语言的简单业务逻辑。
- **服务化。**一个好的 API Gateway 需要能够通过 Admin API 来不停机地管理配置变更,而不是通过一个.conf 文件来人肉地修改配置。
#### 状态数据调度
对于服务调度来说,最难办的就是有状态的服务了。这里的状态是 State,也就是说,有些服务会保存一些数据,而这些数据是不能丢失的,所以,这些数据是需要随服务一起调度的。
一般来说,我们会通过“转移问题”的方法来让服务变成“无状态的服务”。也就是说,会把这些有状态的东西存储到第三方服务上,比如 Redis、MySQL、ZooKeeper,或是 NFS、Ceph 的文件系统中。
这些“转移问题”的方式把问题转移到了第三方服务上,于是自己的 Java 或 PHP 服务中没有状态,但是 Redis 和 MySQL 上则有了状态。所以,我们可以看到,现在的分布式系统架构中出问题的基本都是这些存储状态的服务。
因为数据存储结点在 Scale 上比较困难,所以成了一个单点的瓶颈。
#### 分布式事务一致性的问题
要解决数据结点的 Scale 问题,也就是让数据服务可以像无状态的服务一样在不同的机器上进行调度,这就会涉及数据的 replication 问题。而数据 replication 则会带来数据一致性的问题,进而对性能带来严重的影响。
要解决数据不丢失的问题,只能通过数据冗余的方法,就算是数据分区,每个区也需要进行数据冗余处理。这就是数据副本。当出现某个节点的数据丢失时,可以从副本读到。数据副本是分布式系统解决数据丢失异常的唯一手段。简单来说:
- 要想让数据有高可用性,就得写多份数据。
- 写多份会引起数据一致性的问题。
- 数据一致性的问题又会引发性能问题
在解决数据副本间的一致性问题时,可以使用以下这些技术方案。
- Master-Slave 方案。
- Master-Master 方案。
- 两阶段和三阶段提交方案。
- Paxos 方案。
**关于分布式的事务处理:**https://coolshell.cn/articles/10910.html
#### 状态数据调总结
- 对于应用层上的分布式事务一致性,只有两阶段提交这样的方式。
- 而底层存储可以解决这个问题的方式是通过一些像 Paxos、Raft 或是 NWR 这样的算法和模型来解决。
- 状态数据调度应该是由分布式存储系统来解决的,这样会更为完美。但是因为数据存储的 Scheme 太多,所以,导致我们有各式各样的分布式存储系统,有文件对象的,有关系型数据库的,有 NoSQL 的,有时序数据的,有搜索数据的,有队列的……
数据调度应该是在 IaaS 层的数据存储解决的问题,而不是在 PaaS 层或者 SaaS 层来解决的。
在 IaaS 层上解决这个问题,一般来说有三种方案,
一种是使用比较廉价的开源产品,如:NFS、Ceph、TiDB、CockroachDB、ElasticSearch、InfluxDB、MySQL Cluster 和 Redis Cluster 之类的;另一种是用云计算厂商的方案。当然,如果不差钱的话,可以使用更为昂贵的商业网络存储方案。
### Pass平台的本质

下面这三件事是 PaaS 跟传统中间件最大的差别。
- **服务化是 PaaS 的本质**。软件模块重用,服务治理,对外提供能力是 PaaS 的本质。
- **分布式是 PaaS 的根本特性**。多租户隔离、高可用、服务编排是 PaaS 的基本特性。
- **自动化是 PaaS 的灵魂**。自动化部署安装运维,自动化伸缩调度是 PaaS 的关键。
## PaaS 平台的总体架构

在 Docker+Kubernetes 层之上,我们看到了两个相关的 PaaS 层。一个是 PaaS 调度层,很多人将其称为 iPaaS;另一个是 PaaS 能力层,通常被称为 aPaaS。没有 PaaS 调度层,PaaS 能力层很难被管理和运维,而没有 PaaS 能力层,PaaS 就失去了提供实际能力的业务价值。而本文更多的是在讲 PaaS 调度层上的东西。
一个完整的 PaaS 平台会包括以下几部分。
- PaaS 调度层 – 主要是 PaaS 的自动化和分布式对于高可用高性能的管理。
- PaaS 能力服务层 – 主要是 PaaS 真正提供给用户的服务和能力。
- PaaS 的流量调度 – 主要是与流量调度相关的东西,包括对高并发的管理。
- PaaS 的运营管理 – 软件资源库、软件接入、认证和开放平台门户。
- PaaS 的运维管理 – 主要是 DevOps 相关的东西。
## PaaS 平台的生产和运维

### 总结
传统的单体架构系统容量显然是有上限的。同时,为了应对有计划和无计划的下线时间,系统的可用性也是有其极限的。分布式系统为以上两个问题提供了解决方案,并且还附带有其他优势。但是,要同时解决这两个问题决非易事。为了构建分布式系统,我们面临的主要问题如下。
- 分布式系统的硬件故障发生率更高,故障发生是常态,需要尽可能地将运维流程自动化。
- 需要良好地设计服务,避免某服务的单点故障对依赖它的其他服务造成大面积影响。
- 为了容量的可伸缩性,服务的拆分、自治和无状态变得更加重要,可能需要对老的软件逻辑做大的修改。
- 老的服务可能是异构的,此时需要让它们使用标准的协议,以便可以被调度、编排,且互相之间可以通信。
- 服务软件故障的处理也变得复杂,需要优化的流程,以加快故障的恢复。
- 为了管理各个服务的容量,让分布式系统发挥出最佳性能,需要有流量调度技术。
- 分布式存储会让事务处理变得复杂;在事务遇到故障无法被自动恢复的情况下,手动恢复流程也会变得复杂。
- 测试和查错的复杂度增大。
- 系统的吞吐量会变大,但响应时间会变长。
为了解决这些问题,我们深入了解了以下这些解决方案。
- 需要有完善的监控系统,以便对服务运行状态有全面的了解。
- 设计服务时要分析其依赖链;当非关键服务故障时,其他服务要自动降级功能,避免调用该服务。
- 重构老的软件,使其能被服务化;可以参考 SOA 和微服务的设计方式,目标是微服务化;使用 Docker 和 Kubernetes 来调度服务。
- 为老的服务编写接口逻辑来使用标准协议,或在必要时重构老的服务以使得它们有这些功能。
- 自动构建服务的依赖地图,并引入好的处理流程,让团队能以最快速度定位和恢复故障。
- 使用一个 API Gateway,它具备服务流向控制、流量控制和管理的功能。
- 事务处理建议在存储层实现;根据业务需求,或者降级使用更简单、吞吐量更大的最终一致性方案,或者通过二阶段提交、Paxos、Raft、NWR 等方案之一,使用吞吐量小的强一致性方案。
- 通过更真实地模拟生产环境,乃至在生产环境中做灰度发布,从而增加测试强度;同时做充分的单元测试和集成测试以发现和消除缺陷;最后,在服务故障发生时,相关的多个团队同时上线自查服务状态,以最快地定位故障原因。
- 通过异步调用来减少对短响应时间的依赖;对关键服务提供专属硬件资源,并优化软件逻辑以缩短响应时间。
### 基础理论
## [CAP 定理](https://en.wikipedia.org/wiki/CAP_theorem)
CAP 定理是分布式系统设计中最基础,也是最为关键的理论。它指出,分布式数据存储不可能同时满足以下三个条件。
- **一致性(Consistency)**:每次读取要么获得最近写入的数据,要么获得一个错误。
- **可用性(Availability)**:每次请求都能获得一个(非错误)响应,但不保证返回的是最新写入的数据。
- **分区容忍(Partition tolerance)**:尽管任意数量的消息被节点间的网络丢失(或延迟),系统仍继续运行。
也就是说,CAP 定理表明,在存在网络分区的情况下,一致性和可用性必须二选一。而在没有发生网络故障时,即分布式系统正常运行时,一致性和可用性是可以同时被满足的。这里需要注意的是,CAP 定理中的一致性与 ACID 数据库事务中的一致性截然不同。
掌握 CAP 定理,尤其是能够正确理解 C、A、P 的含义,对于系统架构来说非常重要。因为对于分布式系统来说,网络故障在所难免,如何在出现网络故障的时候,维持系统按照正常的行为逻辑运行就显得尤为重要。你可以结合实际的业务场景和具体需求,来进行权衡。
例如,对于大多数互联网应用来说(如门户网站),因为机器数量庞大,部署节点分散,网络故障是常态,可用性是必须要保证的,所以只有舍弃一致性来保证服务的 AP。而对于银行等,需要确保一致性的场景,通常会权衡 CA 和 CP 模型,CA 模型网络故障时完全不可用,CP 模型具备部分可用性。

- CA (consistency + availability),这样的系统关注一致性和可用性,它需要非常严格的全体一致的协议,比如“两阶段提交”(2PC)。CA 系统不能容忍网络错误或节点错误,一旦出现这样的问题,整个系统就会拒绝写请求,因为它并不知道对面的那个结点是否挂掉了,还是只是网络问题。唯一安全的做法就是把自己变成只读的。
- CP (consistency + partition tolerance),这样的系统关注一致性和分区容忍性。它关注的是系统里大多数人的一致性协议,比如:Paxos 算法(Quorum 类的算法)。这样的系统只需要保证大多数结点数据一致,而少数的结点会在没有同步到最新版本的数据时变成不可用的状态。这样能够提供一部分的可用性。
- AP (availability + partition tolerance),这样的系统关心可用性和分区容忍性。因此,这样的系统不能达成一致性,需要给出数据冲突,给出数据冲突就需要维护数据版本。Dynamo 就是这样的系统。
#### Paxos 算法
Paxos 算法,是莱斯利·兰伯特(Lesile Lamport)于 1990 年提出来的一种基于消息传递且具有高度容错特性的一致性算法。但是这个算法太过于晦涩,所以,一直以来都属于理论上的论文性质的东西。
#### Raft 算法
因为 Paxos 算法太过于晦涩,而且在实际的实现上有太多的坑,并不太容易写对。所以,有人搞出了另外一个一致性的算法,叫 Raft。其原始论文是[ In search of an Understandable Consensus Algorithm (Extended Version) ](https://raft.github.io/raft.pdf)寻找一种易于理解的 Raft 算法。这篇论文的译文在 InfoQ 上《[Raft 一致性算法论文译文](http://www.infoq.com/cn/articles/raft-paper)》
Raft 算法和 Paxos 的性能和功能是一样的,但是它和 Paxos 算法的结构不一样,这使 Raft 算法更容易理解并且更容易实现。那么 Raft 是怎样做到的呢?
Raft 把这个一致性的算法分解成了几个部分,一个是领导选举(Leader Selection),一个是日志复制(Log Replication),一个是安全性(Safety),还有一个是成员变化(Membership Changes)。对于一般人来说,Raft 协议比 Paxos 的学习曲线更低,也更平滑。
Raft 协议中有一个状态机,每个结点会有三个状态,分别是 Leader、Candidate 和 Follower。Follower 只响应其他服务器的请求,如果没有收到任何信息,它就会成为一个 Candidate,并开始进行选举。收到大多数人同意选票的人会成为新的 Leader。

一旦选举出了一个 Leader,它就开始负责服务客户端的请求。每个客户端的请求都包含一个要被复制状态机执行的指令。Leader 首先要把这个指令追加到 log 中形成一个新的 entry,然后通过 AppendEntries RPC 并行地把该 entry 发给其他服务器(server)。如果其他服务器没发现问题,复制成功后会给 Leader 一个表示成功的 ACK。
Leader 收到大多数 ACK 后应用该日志,返回客户端执行结果。如果 Follower 崩溃 (crash)或者丢包,Leader 会不断重试 AppendEntries RPC。

几个不错的 Raft 算法的动画演示。
- [Raft – The Secret Lives of Data](http://thesecretlivesofdata.com/raft/)
- [Raft Consensus Algorithm](https://raft.github.io/)
- [Raft Distributed Consensus Algorithm Visualization](http://kanaka.github.io/raft.js/)
#### 逻辑钟和向量钟
后面,业内又搞出来一些工程上的东西,比如 Amazon 的 DynamoDB,其论文[Dynamo: Amazon’s Highly Available Key Value Store](http://bnrg.eecs.berkeley.edu/~randy/Courses/CS294.F07/Dynamo.pdf) 的影响力也很大。这篇论文中讲述了 Amazon 的 DynamoDB 是如何满足系统的高可用、高扩展和高可靠要求的,其中还展示了系统架构是如何做到数据分布以及数据一致性的。
GFS 采用的是查表式的数据分布,而 DynamoDB 采用的是计算式的,也是一个改进版的通过虚拟结点减少增加结点带来数据迁移的一致性哈希。另外,这篇论文中还讲述了一个 NRW 模式用于让用户可以灵活地在 CAP 系统中选取其中两项,这使用到了 Vector Clock——向量时钟来检测相应的数据冲突。最后还介绍了使用 Handoff 的机制对可用性的提升。
这篇文章中有几个关键的概念,一个是 Vector Clock,另一个是 Gossip 协议。
提到向量时钟就需要提一下逻辑时钟。所谓逻辑时间,也就是在分布系统中为了解决消息有序的问题,由于在不同的机器上有不同的本地时间,这些本地时间的同步很难搞,会导致消息乱序。
于是 Paxos 算法的发明人兰伯特(Lamport)搞了个向量时钟,每个系统维护一个本地的计数器,这就是所谓的逻辑时钟。每执行一个事件(例如向网络发送消息,或是交付到应用层)都对这个计数器做加 1 操作。当跨系统的时候,在消息体上附着本地计算器,当接收端收到消息时,更新自己的计数器(取对端传来的计数器和自己当成计数器的最大值),也就是调整自己的时钟。
逻辑时钟可以保证,如果事件 A 先于事件 B,那么事件 A 的时钟一定小于事件 B 的时钟,但是返过来则无法保证,因为返过来没有因果关系。所以,向量时钟解释了因果关系。向量时钟维护了数据更新的一组版本号(版本号其实就是使用逻辑时钟)。
假如一个数据需要存在三个结点上 A、B、C。那么向量维度就是 3,在初始化的时候,所有结点对于这个数据的向量版本是 [A:0, B:0, C:0]。当有数据更新时,比如从 A 结点更新,那么,数据的向量版本变成 [A:1, B:0, C:0],然后向其他结点复制这个版本,其在语义上表示为我当前的数据是由 A 结果更新的,而在逻辑上则可以让分布式系统中的数据更新的顺序找到相关的因果关系。
这其中的逻辑关系,你可以看一下[ 马萨诸塞大学课程 Distributed Operating System ](http://lass.cs.umass.edu/~shenoy/courses/spring05/lectures.html)中第 10 节[ Clock Synchronization ](http://lass.cs.umass.edu/~shenoy/courses/spring05/lectures/Lec10.pdf)这篇讲议。关于 Vector Clock,你可以看一下[ Why Vector Clocks are Easy](http://basho.com/posts/technical/why-vector-clocks-are-easy/)和[Why Vector Clocks are Hard](http://basho.com/posts/technical/why-vector-clocks-are-hard/) 这两篇文章。
#### Gossip 协议
另外,DynamoDB 中使用到了 Gossip 协议来做数据同步,这个协议的原始论文是 [Efficient Reconciliation and Flow Control for Anti-Entropy Protocols](https://www.cs.cornell.edu/home/rvr/papers/flowgossip.pdf)。Gossip 算法也是 Cassandra 使用的数据复制协议。这个协议就像八卦和谣言传播一样,可以 “一传十、十传百”传播开来。但是这个协议看似简单,细节上却非常麻烦。
根据这篇论文,节点之间存在三种通信方式。
- push 方式。A 节点将数据 (key,value,version) 及对应的版本号推送给 B 节点,B 节点更新 A 中比自己新的数据。
- pull 方式。A 仅将数据 key,version 推送给 B,B 将本地比 A 新的数据 (key,value,version) 推送给 A,A 更新本地。
- push/pull 方式。与 pull 类似,只是多了一步,A 再将本地比 B 新的数据推送给 B,B 更新本地。
如果把两个节点数据同步一次定义为一个周期,那么在一个周期内,push 需通信 1 次,pull 需 2 次,push/pull 则需 3 次。从效果上来讲,push/pull 最好,理论上一个周期内可以使两个节点完全一致。直观感觉上,也是 push/pull 的收敛速度最快。
另外,每个节点上的又需要一个协调机制,也就是如何交换数据能达到最快的一致性——消除节点的不一致性。上面所讲的 push、pull 等是通信方式,协调是在通信方式下的数据交换机制。
关于 Gossip 的一些图示化的东西,可以看一下动画[gossip visualization](https://rrmoelker.github.io/gossip-visualization/)。
#### 分布式数据库方面
数据库方面的一些论文。
一篇是 AWS Aurora 的论文 [Amazon Aurora: Design Considerations for High Throughput Cloud –Native Relation Databases](http://www.allthingsdistributed.com/files/p1041-verbitski.pdf)。
Aurora 是 AWS 将 MySQL 的计算和存储分离后,计算节点 scale up,存储节点 scale out。并把其 redo log 独立设计成一个存储服务,把分布式的数据方面的东西全部甩给了底层存储系统。从而提高了整体的吞吐量和水平的扩展能力。
Aurora 要写 6 份拷贝,但是其只需要把一个 Quorum 中的日志写成功就可以了。如下所示。可以看到,将存储服务做成一个跨数据中心的服务,提高数据库容灾,降低性能影响。

对于存储服务的设计,核心的原理就是 latency 一定要低,毕竟写 6 个 copy 是一件开销很大的事。所以,基本上来说,Aurora 用的是异步模型,然后拼命地做并行处理,其中用到的也是 Gossip 协议。如下所示。

在上面这个图中,我们可以看到,完成前两步,就可以 ACK 回调用方。也就是说,只要数据在本地落地了,就可以返回成功了。然后,对于六个副本,这个 log 会同时发送到 6 个存储结点,只需要有大于 4 个成功 ACK,就算写成功了。第 4 步我们可以看到用的是 Gossip 协议。然后,第 5 步产生 cache 页,便于查询。第 6 步在 S3 做 Snapshot,类似于 Checkpoint。
### 经典资料
- Distributed systems theory for the distributed systems engineer
- FLP Impossibility Result
- An introduction to distributed systems
- Distributed Systems for fun and profit
- Distributed Systems: Principles and Paradigms
- Scalable Web Architecture and Distributed Systems
- Principles of Distributed Systems
- Making reliable distributed systems in the presence of software errors
- Designing Data Intensive Applications
点赞
回复
X