当前仅显示指定条件回帖 [ 展开查看全部 ]
02-15 11:07
文件名称:
3.8.5.6Huggingface的量化基础.md
所在目录:
3.AI模块 / 3.8【LLM】大语言模型 / 3.8.5LLM实操项目
文件大小:
23.58 KB
下载地址:
文本预览:
# Huggingface的量化基础
> Author:bread
## 介绍
- 学习使用int 8,float16,bfloat16(brain flot16) 来压缩模型
- 学习压缩算法,存储一个32位数
## Class 1:处理大型模型
随着模型平均大小的增加,平均参数数量已达到了700亿的数量级,这是一个非常庞大的数据。然而像t4这样的低端计算卡,也只有16g的 RAM(运行内存)。所以,运行这些先进的模型仍然是一种挑战。这个时候,就要求在不需要访问高内存的情况下有效的运行这些模型。所以,社区现在面临的主要挑战是让这些模型可以通过压缩模型来访问。
而目前,最先进的模型压缩方法(如pruning and knowledge distillation)花费更多的时间去做量化。
1.pruning(修剪):pruning只是包括删除模型中的层级,对模型的决策没有很重大的影响。他只是删除一些在计算过程中权重不大的某些指标的层级。
2.knowledge distillation(知识蒸馏):使用原模型(instructor)训练一个更小的模型(student)。知识蒸馏除了会难以避免地丢失一些信息,最主要的难题是需要确保你有足够的计算来拟合原始模型并且从中获取预测,以便可以再计算损失的时候将他们发送到原模型。但是如果你要提炼非常大的模型,那么他的成本将会指数级上涨😱。
### 量化
量化是以较低精度表示模型权重,例如下图的小矩阵,里面存储着一个小模型的一些参数。由于矩阵以float32格式存储(这是大多数模型的默认存储数据类型)它为每个参数分配四个字节,8bit的四倍精读,因此如下矩阵占用 36 bytes。

如果以八位精读量化权重矩阵,那么每个参数将只得到 1 byte。因此,我们只需要9 bytes就可以存储整个权重矩阵。
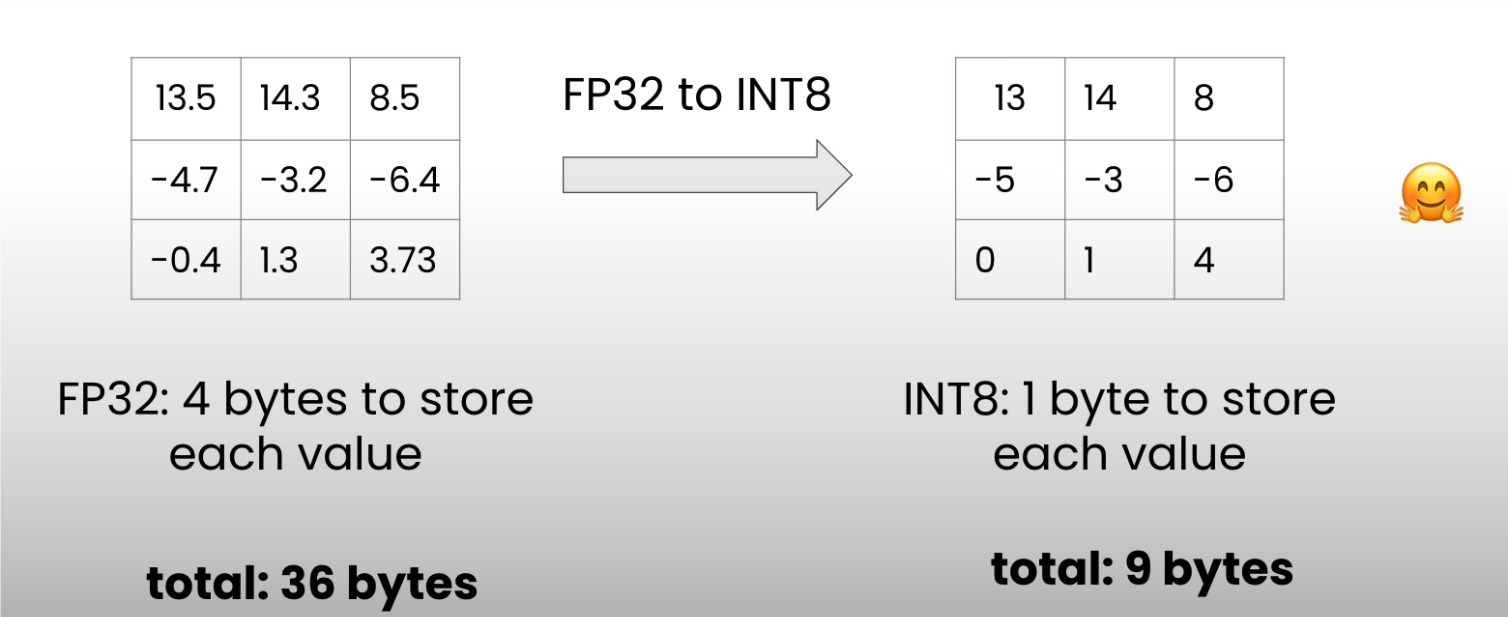
然而,这是有代价的,那就是量化误差(quantization error)。最先进的量化方法背后的主要挑战是降低这种误差,尽可能避免任何性能下降。
## Class 2:数据类型和大小
### 1.unsigned integer:
用于表示正整数,n位无符号整数的范围是0到2ⁿ-1,例如八位无符号整数的最小值为0,最大值为255。而计算机分配一个八个比特的空间来存储这个八位整数,如下图所示
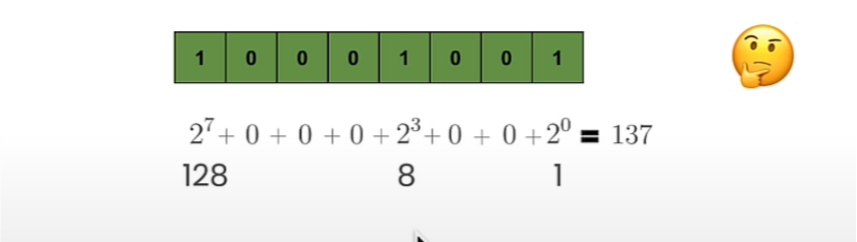
对于它的表示方法这里就不多做赘述了。这里还要讲讲有符号整数,有符号整数用来表示负整数或正整数,他有多种表现形式,但由于2‘s补码(2’s Complement Code)的常见性,我们今天研究的只有2‘s补码。它的范围是-2^n-1^次幂到2^n-1^-1。因此,对于8位有符号整数,最小值为-128,最大值为127。与无符号整数的区别在于最后一个位置的数字。正如你在下图看到的

这个值是负数。因此,如果我们处理与前面相同的序列,我们需要在数字前添加一个负号。结果为-(128+1)=-129。
### 2.integer-pytorch
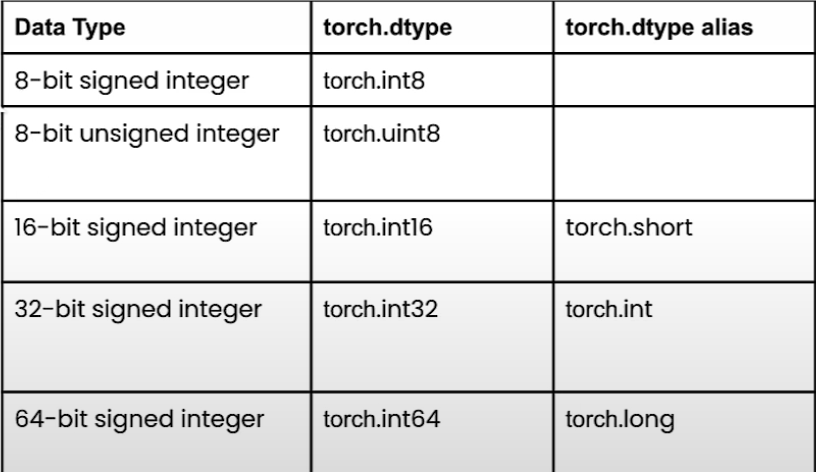
在pytorch中创建具有整数数据类型的数据并非难事,只需要正确设置``torch.dtype``。如下表所示,要创建一个8位有符号整数,只需要设置``torch.int8``作为``torrch.dtype``
为此,我们将使用``torch.iinfo``,代码如下所示。
```python
#torch.uint8
torch.iinfo(torch.uint8)
iinfo(min=0, max=255, dtype=uint8)
```
以下是jupyter notebook代码,用来本地运行并测试代码
```python
!pip install pytorch==2.1.1
##使用torch库
import torch
##8位无符号整数的信息
torch.iinfo(torch.uint8)
iinfo(min=0, max=255, dtype=uint8)
##8位有符号整数的信息
torch.iinfo(torch.int8)
iinfo(min=-128, max=127, dtype=int8)
##下面就该轮到你们自己完成了!
##64位有符号整数的信息
##32位有符号整数的信息
##16位有符号整数的信息
```
### 3.floating
讨论完了整数,接下来赶到战场的是浮点数。浮点数由三个部分组成:
- 符号:正/负(始终为1位)
- 指数(范围):影响数值的可表示范围
- 小数部分(精度):影响数值的精度
FP32、BF16、FP16、FP8 是具有特定数量的指数和小数部分位数的浮点格式。
例如FP32
```
FP32
符号:1位
指数(范围):8位
小数部分(精度):23位
总计:32位
```
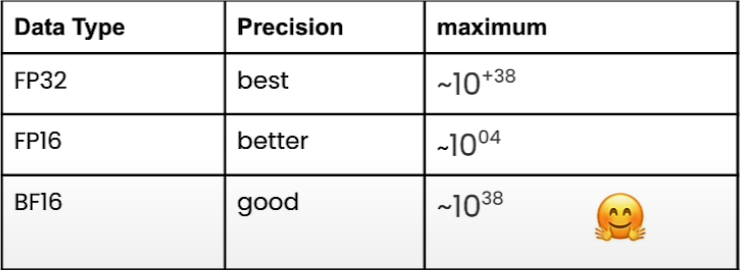
下图展示了FP32可以存储多大和多小的数字
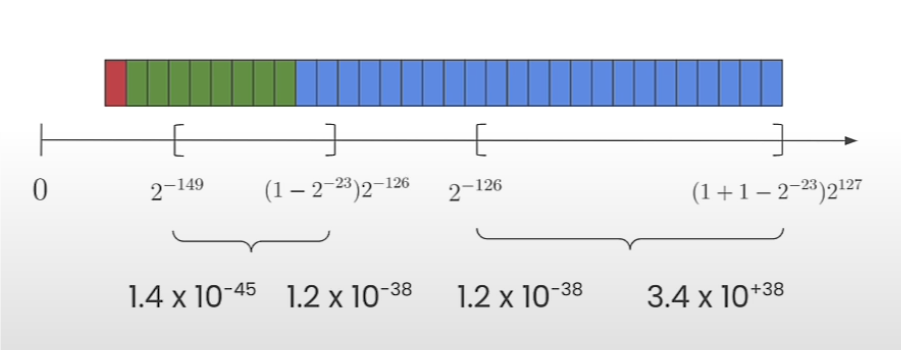
这类数据类型在机器学习中非常重要,因为大多数模型将他的权重存储在FP32中。
FP16 (Half-Precision Floating-Point) 的表示方式与整数和分数部分的位数有些不同。FP16 使用 1 位符号位、5 位指数位和 10 位尾数位。具体的位数分配如下:
- 符号位 (Sign Bit, S):1 位
- 指数位 (Exponent Bits, E):5 位
- 尾数位 (Mantissa Bits, M):10 位
根据 IEEE 754 标准,FP16 的表示范围和精度如下:
- 指数范围是 -14 到 15(经过偏移量为 15 的偏移后)。
- 尾数部分是 10 位,有效尾数是 1 + 尾数部分。
- 最小的非零正数:2^(-14) * 2^(-10) ≈ 6.10 x 10^-5(次正规数)。
- 最大值:2^(15) * (2 - 2^-10) ≈ 65504。
而bfloat16 的位分配如下:
- 符号位 (Sign Bit, S):1 位
- 指数位 (Exponent Bits, E):8 位
- 尾数位 (Mantissa Bits, M):7 位
由于它的指数位与 FP32 的指数位相同,因此它们的指数范围相同。这意味着 bfloat16 的指数范围与 FP32 一样,从 -126 到 +127(偏移量为 127 的偏移后)。
根据 IEEE 754 标准,bfloat16 的表示范围和精度如下:
- 指数范围是 -126 到 127(经过偏移量为 127 的偏移后)。
- 尾数部分是 7 位,有效尾数是 1 + 尾数部分。
- 最小的非零正数:2^(-126) ≈ 1.18 x 10^-38(次正规数)。
- 最大值:2^(127) * (2 - 2^-7) ≈ 3.39 x 10^38。
以下是浮点数在pytorch中的类型表:
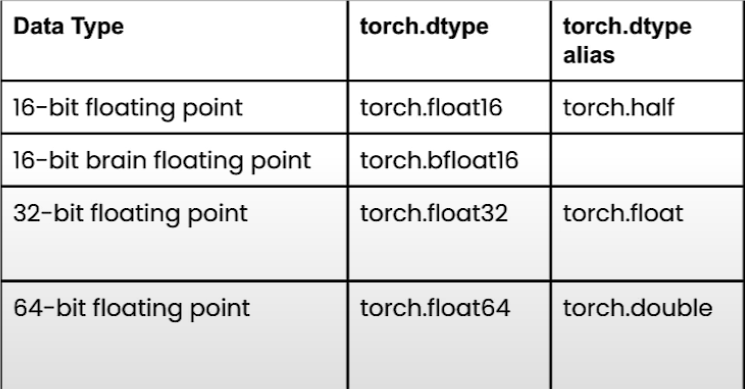
要在 PyTorch 中创建一个 16 位的brain浮点数,只需将 `dtype` 设置为 `torch.bfloat16`。
现在,让我们来看看将一个python值转化为具有特定类型的pytorch张量时会发生什么
```python
# 默认情况下,Python 使用 FP64 存储浮点数数据
value = 1/3
# 使用 format 函数将浮点数打印出后 60 位小数点
format(value, '.60f')
#大概率打出来的是0.33333333333333+后面的近似值
#现在,让我们创建一个张量,类型为torch.bfloat16
tensor_bf16 =
torch.tenser(value, dtype=torch.bfloat16)
#打印它,你将会得到相同的答案
print(f"fp64 tensor: {format(tensor_fp64.item(), '.60f')}")
#以下就自己跑跑吧😋
# 32 位浮点数
tensor_fp32 = torch.tensor(value, dtype=torch.float32)
print(f"fp32 tensor: {format(tensor_fp32.item(), '.60f')}")
# 16 位浮点数
tensor_fp16 = torch.tensor(value, dtype=torch.float16)
print(f"fp16 tensor: {format(tensor_fp16.item(), '.60f')}")
# 16 位brain浮点数
tensor_bf16 = torch.tensor(value, dtype=torch.bfloat16)
print(f"bf16 tensor: {format(tensor_bf16.item(), '.60f')}")
```
到这里我们应该可以得出一个结论
**数据有的位数越少,近似值的精确度就越低,而对于bfloat16,正如我们之前看到的,精度比FP16差,但是bfloat16的表示范围大于FP16。**
可以通过`torch.finfo`函数来检验这一点
```python
# 获取 16 位brain浮点数的信息
torch.finfo(torch.bfloat16)
'''
返回:finfo(resolution=0.0078125,
min=-3.3895313892515355e+38,
max=3.3895313892515355e+38,
eps=0.0078125,
tiny=1.1754943508222875e-38)
'''
# 获取 32 位浮点数的信息
torch.finfo(torch.float32)
# 获取 16 位浮点数的信息
torch.finfo(torch.float16)
# 获取 64 位浮点数的信息
torch.finfo(torch.float64)
```
### 4.Downcasting(向下转换)
向下转换 (Downcasting) 是指将数据从一种更高精度的数值类型转换为一种更低精度的数值类型。
例如,将 64 位浮点数 (float64) 转换为 32 位浮点数 (float32),或将 32 位浮点数 (float32) 转换为 16 位浮点数 (float16) 或 16 位brain浮点数 (bfloat16)。
向下转换在深度学习中尤为重要,因为它可以显著减少模型的内存占用和计算时间,但也会带来精度损失。
```python
tenser_fp32 = torch.rand(1000, dtype=torch.float32)
tenser_fp32[:5]
#查看前五个值
#tensor([0.3315, 0.0457, 0.8335, 0.0303, 0.9850])
tenser_fp32_TO_BF16 = tenser_fp32.to(dtype=torch.bfloat16)
tenser_fp32_TO_BF16[:5]
#tensor([0.3320, 0.0457, 0.8320, 0.0303, 0.9844], dtype=torch.bfloat16)
#接下来是向下转换对乘法的影响
m_float32 = torch .dot(tenser_fp32, tenser_fp32)
m_float32
m_bfloat16 = torch.dot(tenser_fp32_TO_BF16, tenser_fp32_TO_BF16)
m_bfloat16
```
对于向下转换来说,它的优缺点有以下几点:
**优势:**
- **减少内存占用**
- 更高效地使用 GPU 内存。
- 使得能够训练更大的模型。
- 允许使用更大的批次大小。
- **提高计算能力和速度**
- 使用低精度(如 fp16、bf16)的计算可以比 fp32 更快,因为它们占用的内存更少。
- 这取决于硬件(例如 Google TPU、NVIDIA A100)。
**劣势:**
- **精度较低**:由于使用了更少的内存,因此计算的精度会降低。
## Class 3:按数据类型加载模型
### 第三课:使用不同数据类型加载机器学习模型
在本实验中,您将学习如何在不同的数据类型下加载机器学习模型。
### 加载 Dummy Model(示例模型):
从 `helper.py` 文件中加载 Dummy Model。
```python
from helper import DummyModel
model = DummyModel()
model
```
创建一个函数来检查模型中参数的数据类型:
```python
def print_param_dtype(model):
for name, param in model.named_parameters():
print(f"{name} is loaded in {param.dtype}")
print_param_dtype(model)
```
### 模型转换:float16
将模型转换为另一种精度。
```python
# float 16
model_fp16 = DummyModel().half()
#检查参数的数据类型。
print_param_dtype(model_fp16)
model_fp16
#使用模型进行简单推理。
import torch
dummy_input = torch.LongTensor([[1, 0], [0, 1]])
# 使用 float32 模型进行推理
logits_fp32 = model(dummy_input)
logits_fp32
# 使用 float16 模型进行推理
try:
logits_fp16 = model_fp16(dummy_input)
except Exception as error:
print("\033[91m", type(error).__name__, ": ", error, "\033[0m")
```
### 模型转换:bfloat16
关于 deepcopy 的注意事项:copy.deepcopy 会创建一个与原始模型独立的副本。对副本所做的修改不会影响原始模型,因为您创建的是一个“深拷贝”。有关更多详细信息,请参阅 Python 文档中关于 copy 库的内容。
```python
from copy import deepcopy
model_bf16 = deepcopy(model)
model_bf16 = model_bf16.to(torch.bfloat16)
print_param_dtype(model_bf16)
logits_bf16 = model_bf16(dummy_input)
#现在,比较 logits_fp32 和 logits_bf16 之间的差异。
mean_diff = torch.abs(logits_bf16 - logits_fp32).mean().item()
max_diff = torch.abs(logits_bf16 - logits_fp32).max().item()
print(f"Mean diff: {mean_diff} | Max diff: {max_diff}")
```
### 使用不同数据类型的流行生成模型
加载[Salesforce/blip-image-captioning-base](https://huggingface.co/Salesforce/blip-image-captioning-base)以进行图像字幕生成。
要获取 Younes 提供的示例代码:
点击 "Model Card" 选项卡。
在右侧,点击 “<> Use in Transformers” 按钮,您将看到一个弹出窗口,内含加载此模型的示例代码。
```python
# 直接加载模型
from transformers import AutoProcessor, AutoModelForSeq2SeqLM
processor = AutoProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = AutoModelForSeq2SeqLM.from_pretrained("Salesforce/blip-image-captioning-base")
#要查看带有示例的代码,请点击弹出窗口底部的 "Read model documentation"。它会打开一个新标签。https://huggingface.co/docs/transformers/main/en/model_doc/blip#transformers.BlipForConditionalGeneration
# 在页面中稍微向下滚动,越过 "parameters" 部分,您会看到 "Examples:"。
from PIL import Image
import requests
from transformers import AutoProcessor, BlipForConditionalGeneration
processor = AutoProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "A picture of"
inputs = processor(images=image, text=text, return_tensors="pt")
outputs = model(**inputs)
#检查模型的默认数据类型
from transformers import BlipForConditionalGeneration
model_name = "Salesforce/blip-image-captioning-base"
model = BlipForConditionalGeneration.from_pretrained(model_name)
# inspect the default data types of the model
# print_param_dtype(model)
#检查模型的内存占用。
fp32_mem_footprint = model.get_memory_footprint()
print("Footprint of the fp32 model in bytes: ", fp32_mem_footprint)
print("Footprint of the fp32 model in MBs: ", fp32_mem_footprint/1e+6)
#以 bfloat16 加载相同的模型。
model_bf16 = BlipForConditionalGeneration.from_pretrained(
model_name,
torch_dtype=torch.bfloat16
)
bf16_mem_footprint = model_bf16.get_memory_footprint()
# 获取相对差异
relative_diff = bf16_mem_footprint / fp32_mem_footprint
print("Footprint of the bf16 model in MBs: ", bf16_mem_footprint/1e+6)
print(f"Relative diff: {relative_diff}")
```
### 模型性能:float32 vs bfloat16
现在,比较两种模型的生成结果。
```python
from transformers import BlipProcessor
processor = BlipProcessor.from_pretrained(model_name)
#加载图像。
from helper import load_image, get_generation
from IPython.display import display
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
image = load_image(img_url)
display(image.resize((500, 350)))
results_fp32 = get_generation(model, processor, image, torch.float32)
print("fp32 Model Results:\n", results_fp32)
results_bf16 = get_generation(model_bf16, processor, image, torch.bfloat16)
print("bf16 Model Results:\n", results_bf16)
#对于 Hugging Face Transformers 库,默认的数据类型是 float32。您可以将 "默认数据类型" 设置为您所需要的
desired_dtype = torch.bfloat16
torch.set_default_dtype(desired_dtype)
dummy_model_bf16 = DummyModel()
print_param_dtype(dummy_model_bf16)
#同样,您可以将默认数据类型重置为 float32。
torch.set_default_dtype(torch.float32)
print_param_dtype(dummy_model_bf16)
```
### 注意
您刚刚使用了一种简单的量化形式,将模型的参数保存为更紧凑的数据类型(bfloat16)。在推理过程中,模型在这种数据类型下执行计算,其激活也是在这种数据类型下进行的。
在下一课中,您将使用另一种量化方法 "线性量化",该方法通过在推理过程中从压缩的数据类型转换回原始的 FP32 数据类型,使量化模型的性能更接近原始模型。
## Class 4:量化理论
在本实验中,您将执行 Linear Quantization(线性量化)。
这是最流行的量化方案,他用于大多数最先进的量化方法。
然后,我们将使用Huggingface的量化工具包Quanto将线性量化应用在真实模型。
量化是将大型的set映射到一小部分值的过程。量化有很多种,在本节课,我们将重点介绍线性量化,让我们来看看如何对简单张量执行8位量化,我们将从float32变为8-int
让我们先来看看这个随机数矩阵,他的数据是float32类型,我们该如何在不丢失太多信息的情况下将float32权重转换为int8权重呢
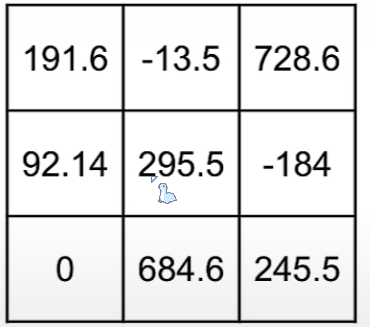
你可以将此矩阵中最大的数(在这是728.6)映射到int8可以存储的最大值(127)
同样,您可以将此矩阵的最大负数(在本例中为负 184)映射到 int8 可以存储的最小值,即负 128。
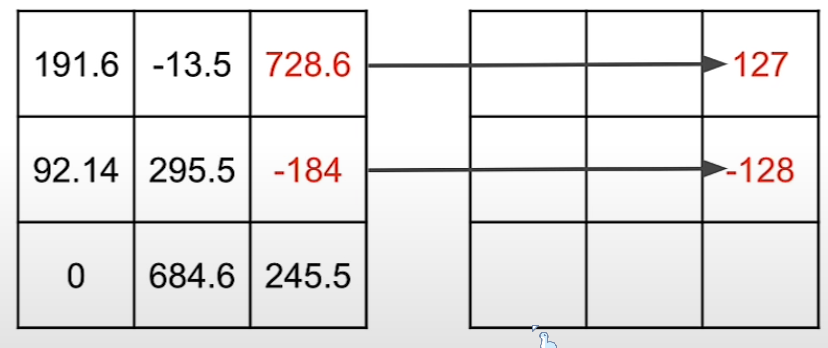
我们还可以按照线性映射映射其余值进行映射。
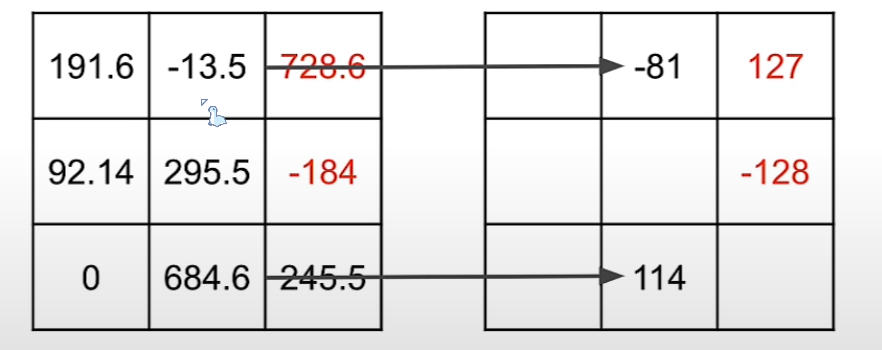
ok这就是简单量化了张量。
接下来,就可以删除原始张量以释放空间,最终我们会得到量化的张量以及用于执行线性映射的参数s和z。“s”代表比例尺,“z”代表零点,到这里,看上去我们节省了很多空间,但我们要怎么得到原来的数据呢?
答案是我们没办法得到与原始张量完全相同的张量,但是你可以使用遵循用于量化原始张量的线性关系的量化
#### 需要安装的库
如果您在本地机器上运行,可以安装以下内容:
```python
!pip install transformers==4.35.0
!pip install quanto==0.0.11
!pip install torch==2.1.1
```
> 请注意,由于硬件内存限制,为了向所有人免费提供本课程,您将在此处运行的代码适用于 T5-FLAN 模型,而不是 EleutherAI AI Pythia 模型。
> 对于 T5-FLAN 模型,如果您在本地运行,这里还有一个需要安装的库:
```python
!pip install sentencepiece==0.2.0
```
#### 不进行量化
```python
model_name = "google/flan-t5-small"
import sentencepiece as spm
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-small")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-small")
input_text = "Hello, my name is "
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
from helper import compute_module_sizes
module_sizes = compute_module_sizes(model)
print(f"The model size is {module_sizes[''] * 1e-9} GB")
```
#### 量化模型(8位精度)
```python
from quanto import quantize, freeze
import torch
quantize(model, weights=torch.int8, activations=None)
print(model)
```
#### 冻结模型
```python
freeze(model)
module_sizes = compute_module_sizes(model)
print(f"The model size is {module_sizes[''] * 1e-9} GB")
```
#### 在量化模型上尝试运行推理
```python
input_text = "Hello, my name is "
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
#### 不进行量化
```python
#加载EleutherAI/pythia-410m模型和tokenizer。
from transformers import AutoModelForCausalLM
model_name = "EleutherAI/pythia-410m"
model = AutoModelForCausalLM.from_pretrained(model_name, low_cpu_mem_usage=True)
print(model.gpt_neox)
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
#编写一个(文本)句子的开头,让模型完成。
text = "Hello my name is"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=10)
outputs
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
#使用helper函数compute_module_sizes计算模型的大小。
from helper import compute_module_sizes
module_sizes = compute_module_sizes(model)
print(f"The model size is {module_sizes[''] * 1e-9} GB")
print(model.gpt_neox.layers[0].attention.dense.weight)
```
#### 8位量化
```python
from quanto import quantize, freeze
import torch
quantize(model, weights=torch.int8, activations=None)
# 执行量化后
print(model.gpt_neox)
print(model.gpt_neox.layers[0].attention.dense.weight)
# 冻结模型
freeze(model)
print(model.gpt_neox.layers[0].attention.dense.weight)
# 获取量化后模型的大小
module_sizes = compute_module_sizes(model)
print(f"The model size is {module_sizes[''] * 1e-9} GB")
# 量化模型后运行推理
outputs = model.generate(**inputs, max_new_tokens=10)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
### 比较“线性量化”与“降级”
回顾一下本课中的“线性量化”方法与上一课中的“降级”方法之间的区别:
当降级一个模型时,您将模型的参数转换为更紧凑的数据类型(bfloat16)。在推理过程中,模型使用这种数据类型进行计算,其激活也是这种数据类型。降级可能适用于bfloat16数据类型,但使用任何更小的数据类型可能会导致模型性能下降,并且如果您转换为整数数据类型(如本课中的int8),则无法工作。
在本课中,您使用了另一种量化方法,“线性量化”,它使得量化模型在推理过程中从压缩数据类型转换回原始的FP32数据类型,从而保持性能更接近原始模型。因此,当模型进行预测时,它是用FP32进行矩阵乘法,激活也是FP32。这使得您可以将模型量化为比bfloat16更小的数据类型,例如本例中的int8。
### 这只是开始…
这门课程旨在作为量化领域的入门介绍。🐣
如果您喜欢这门课程,您可以考虑给出评分,并分享您喜欢的内容。💕
如果您不喜欢这门课程,您也可以分享一下您认为可以改进的地方。🙏
## Class 5:量化LLMs
在本节课上,我们将看看将最先进的量化应用于大语言模型。例如,量化是否可以帮助我们微调LLM?毫无疑问,答案是肯定的。让我们看看该如何操作。
就像我们之前所说,量化是关于以某种方式压缩模型权重。
近期的一些SOTA(State-of-the-Art)量化方法,包括:
- LLM.INT8(仅8位)- Aug 2022 - Dettmers et al.
- QLoRA(仅4位)- May 2023 - Dettmers et al.
- AWQ - Jun 2023 - Lin et al.
- GPTQ - Oct 2022 - Frantar et al.
- SmoothQuant - Nov 2022 - Xiao et al.
三种最新的SOTA(State-of-the-Art)量化方法,分别是:
- QuIP# - Jul 2023 - Tseng et al.
- HQQ - November 2023 - Badri et al.
- AQLM - Feb 2024 - Egiazarian et al.
这些方法的设计目标是使LLMs更小、更快,同时最小化性能下降。它们都是开源的。
一些量化方法需要校准(也见上一课)
校准:
- 在数据集上进行推理
- 优化量化参数以最小化量化误差
许多量化论文都应用于LLM。
如果你将这些方法应用于其他模型(而不是LLM),你可能需要调整量化方法。
一些量化方法可以直接应用于任何模型而无需调整。
例如,自然语言处理、计算机视觉、音频、多模态。
“Ready to use”,(“out of the box”) 量化方法:
- Linear quantization (covered in this course)
- LLM.INT8 (only 8-bit)
- QLoRA (only 4-bit)
- HQQ (up to 2-bit)
Llama2 70B是一个70B参数的模型,例如Llama2 70B。它以32位精度在FP32中存储了280GB的数据。如果以4位精度存储,则可以减少到40GB。因此,存储大小减少了约7倍(280GB/40GB)。
Llama2 7B是一个7B参数的模型。它以32位精度在FP32中存储了28GB的数据。如果以4位精度存储,则可以减少到约4GB,并且这种格式被称为“GGUF”。该模型可以在计算机上运行。
#### 微调量化模型的好处,具体包括:
从量化中恢复准确性
为特定用例和应用程序定制模型。
以量化版本最佳执行的方式微调模型。
- 与训练后量化 (PTQ) 技术不兼容。
- 本课程中学到的线性量化方法是训练后量化的一个示例。
## 结论
恭喜你完成了这个短期课程,你已经了解了机器学习中一些常见的表示数据类型,例如整数和浮点数,以及如何使用不同的数据类型加载AI模型。
你还了解到了模型量化背后的基本概念,以及线性量化的工作原理。
你使用Quanto库以8位精读量化任何pytorch模型。然后,我们了解了量化的一些应用LLMs,例如最近最先进的量化方法LLMs。
有了这些知识,你将能够更好地了解模型压缩,并为你的使用选择最佳的量化技术💡
> Author:bread
## 介绍
- 学习使用int 8,float16,bfloat16(brain flot16) 来压缩模型
- 学习压缩算法,存储一个32位数
## Class 1:处理大型模型
随着模型平均大小的增加,平均参数数量已达到了700亿的数量级,这是一个非常庞大的数据。然而像t4这样的低端计算卡,也只有16g的 RAM(运行内存)。所以,运行这些先进的模型仍然是一种挑战。这个时候,就要求在不需要访问高内存的情况下有效的运行这些模型。所以,社区现在面临的主要挑战是让这些模型可以通过压缩模型来访问。
而目前,最先进的模型压缩方法(如pruning and knowledge distillation)花费更多的时间去做量化。
1.pruning(修剪):pruning只是包括删除模型中的层级,对模型的决策没有很重大的影响。他只是删除一些在计算过程中权重不大的某些指标的层级。
2.knowledge distillation(知识蒸馏):使用原模型(instructor)训练一个更小的模型(student)。知识蒸馏除了会难以避免地丢失一些信息,最主要的难题是需要确保你有足够的计算来拟合原始模型并且从中获取预测,以便可以再计算损失的时候将他们发送到原模型。但是如果你要提炼非常大的模型,那么他的成本将会指数级上涨😱。
### 量化
量化是以较低精度表示模型权重,例如下图的小矩阵,里面存储着一个小模型的一些参数。由于矩阵以float32格式存储(这是大多数模型的默认存储数据类型)它为每个参数分配四个字节,8bit的四倍精读,因此如下矩阵占用 36 bytes。

如果以八位精读量化权重矩阵,那么每个参数将只得到 1 byte。因此,我们只需要9 bytes就可以存储整个权重矩阵。

然而,这是有代价的,那就是量化误差(quantization error)。最先进的量化方法背后的主要挑战是降低这种误差,尽可能避免任何性能下降。
## Class 2:数据类型和大小
### 1.unsigned integer:
用于表示正整数,n位无符号整数的范围是0到2ⁿ-1,例如八位无符号整数的最小值为0,最大值为255。而计算机分配一个八个比特的空间来存储这个八位整数,如下图所示

对于它的表示方法这里就不多做赘述了。这里还要讲讲有符号整数,有符号整数用来表示负整数或正整数,他有多种表现形式,但由于2‘s补码(2’s Complement Code)的常见性,我们今天研究的只有2‘s补码。它的范围是-2^n-1^次幂到2^n-1^-1。因此,对于8位有符号整数,最小值为-128,最大值为127。与无符号整数的区别在于最后一个位置的数字。正如你在下图看到的

这个值是负数。因此,如果我们处理与前面相同的序列,我们需要在数字前添加一个负号。结果为-(128+1)=-129。
### 2.integer-pytorch
在pytorch中创建具有整数数据类型的数据并非难事,只需要正确设置``torch.dtype``。如下表所示,要创建一个8位有符号整数,只需要设置``torch.int8``作为``torrch.dtype``

为此,我们将使用``torch.iinfo``,代码如下所示。
```python
#torch.uint8
torch.iinfo(torch.uint8)
iinfo(min=0, max=255, dtype=uint8)
```
以下是jupyter notebook代码,用来本地运行并测试代码
```python
!pip install pytorch==2.1.1
##使用torch库
import torch
##8位无符号整数的信息
torch.iinfo(torch.uint8)
iinfo(min=0, max=255, dtype=uint8)
##8位有符号整数的信息
torch.iinfo(torch.int8)
iinfo(min=-128, max=127, dtype=int8)
##下面就该轮到你们自己完成了!
##64位有符号整数的信息
##32位有符号整数的信息
##16位有符号整数的信息
```
### 3.floating
讨论完了整数,接下来赶到战场的是浮点数。浮点数由三个部分组成:
- 符号:正/负(始终为1位)
- 指数(范围):影响数值的可表示范围
- 小数部分(精度):影响数值的精度
FP32、BF16、FP16、FP8 是具有特定数量的指数和小数部分位数的浮点格式。
例如FP32
```
FP32
符号:1位
指数(范围):8位
小数部分(精度):23位
总计:32位
```
下图展示了FP32可以存储多大和多小的数字

这类数据类型在机器学习中非常重要,因为大多数模型将他的权重存储在FP32中。
FP16 (Half-Precision Floating-Point) 的表示方式与整数和分数部分的位数有些不同。FP16 使用 1 位符号位、5 位指数位和 10 位尾数位。具体的位数分配如下:
- 符号位 (Sign Bit, S):1 位
- 指数位 (Exponent Bits, E):5 位
- 尾数位 (Mantissa Bits, M):10 位
根据 IEEE 754 标准,FP16 的表示范围和精度如下:
- 指数范围是 -14 到 15(经过偏移量为 15 的偏移后)。
- 尾数部分是 10 位,有效尾数是 1 + 尾数部分。
- 最小的非零正数:2^(-14) * 2^(-10) ≈ 6.10 x 10^-5(次正规数)。
- 最大值:2^(15) * (2 - 2^-10) ≈ 65504。

而bfloat16 的位分配如下:
- 符号位 (Sign Bit, S):1 位
- 指数位 (Exponent Bits, E):8 位
- 尾数位 (Mantissa Bits, M):7 位
由于它的指数位与 FP32 的指数位相同,因此它们的指数范围相同。这意味着 bfloat16 的指数范围与 FP32 一样,从 -126 到 +127(偏移量为 127 的偏移后)。
根据 IEEE 754 标准,bfloat16 的表示范围和精度如下:
- 指数范围是 -126 到 127(经过偏移量为 127 的偏移后)。
- 尾数部分是 7 位,有效尾数是 1 + 尾数部分。
- 最小的非零正数:2^(-126) ≈ 1.18 x 10^-38(次正规数)。
- 最大值:2^(127) * (2 - 2^-7) ≈ 3.39 x 10^38。
以下是浮点数在pytorch中的类型表:

要在 PyTorch 中创建一个 16 位的brain浮点数,只需将 `dtype` 设置为 `torch.bfloat16`。
现在,让我们来看看将一个python值转化为具有特定类型的pytorch张量时会发生什么
```python
# 默认情况下,Python 使用 FP64 存储浮点数数据
value = 1/3
# 使用 format 函数将浮点数打印出后 60 位小数点
format(value, '.60f')
#大概率打出来的是0.33333333333333+后面的近似值
#现在,让我们创建一个张量,类型为torch.bfloat16
tensor_bf16 =
torch.tenser(value, dtype=torch.bfloat16)
#打印它,你将会得到相同的答案
print(f"fp64 tensor: {format(tensor_fp64.item(), '.60f')}")
#以下就自己跑跑吧😋
# 32 位浮点数
tensor_fp32 = torch.tensor(value, dtype=torch.float32)
print(f"fp32 tensor: {format(tensor_fp32.item(), '.60f')}")
# 16 位浮点数
tensor_fp16 = torch.tensor(value, dtype=torch.float16)
print(f"fp16 tensor: {format(tensor_fp16.item(), '.60f')}")
# 16 位brain浮点数
tensor_bf16 = torch.tensor(value, dtype=torch.bfloat16)
print(f"bf16 tensor: {format(tensor_bf16.item(), '.60f')}")
```
到这里我们应该可以得出一个结论
**数据有的位数越少,近似值的精确度就越低,而对于bfloat16,正如我们之前看到的,精度比FP16差,但是bfloat16的表示范围大于FP16。**
可以通过`torch.finfo`函数来检验这一点
```python
# 获取 16 位brain浮点数的信息
torch.finfo(torch.bfloat16)
'''
返回:finfo(resolution=0.0078125,
min=-3.3895313892515355e+38,
max=3.3895313892515355e+38,
eps=0.0078125,
tiny=1.1754943508222875e-38)
'''
# 获取 32 位浮点数的信息
torch.finfo(torch.float32)
# 获取 16 位浮点数的信息
torch.finfo(torch.float16)
# 获取 64 位浮点数的信息
torch.finfo(torch.float64)
```
### 4.Downcasting(向下转换)
向下转换 (Downcasting) 是指将数据从一种更高精度的数值类型转换为一种更低精度的数值类型。
例如,将 64 位浮点数 (float64) 转换为 32 位浮点数 (float32),或将 32 位浮点数 (float32) 转换为 16 位浮点数 (float16) 或 16 位brain浮点数 (bfloat16)。
向下转换在深度学习中尤为重要,因为它可以显著减少模型的内存占用和计算时间,但也会带来精度损失。
```python
tenser_fp32 = torch.rand(1000, dtype=torch.float32)
tenser_fp32[:5]
#查看前五个值
#tensor([0.3315, 0.0457, 0.8335, 0.0303, 0.9850])
tenser_fp32_TO_BF16 = tenser_fp32.to(dtype=torch.bfloat16)
tenser_fp32_TO_BF16[:5]
#tensor([0.3320, 0.0457, 0.8320, 0.0303, 0.9844], dtype=torch.bfloat16)
#接下来是向下转换对乘法的影响
m_float32 = torch .dot(tenser_fp32, tenser_fp32)
m_float32
m_bfloat16 = torch.dot(tenser_fp32_TO_BF16, tenser_fp32_TO_BF16)
m_bfloat16
```
对于向下转换来说,它的优缺点有以下几点:
**优势:**
- **减少内存占用**
- 更高效地使用 GPU 内存。
- 使得能够训练更大的模型。
- 允许使用更大的批次大小。
- **提高计算能力和速度**
- 使用低精度(如 fp16、bf16)的计算可以比 fp32 更快,因为它们占用的内存更少。
- 这取决于硬件(例如 Google TPU、NVIDIA A100)。
**劣势:**
- **精度较低**:由于使用了更少的内存,因此计算的精度会降低。
## Class 3:按数据类型加载模型
### 第三课:使用不同数据类型加载机器学习模型
在本实验中,您将学习如何在不同的数据类型下加载机器学习模型。
### 加载 Dummy Model(示例模型):
从 `helper.py` 文件中加载 Dummy Model。
```python
from helper import DummyModel
model = DummyModel()
model
```
创建一个函数来检查模型中参数的数据类型:
```python
def print_param_dtype(model):
for name, param in model.named_parameters():
print(f"{name} is loaded in {param.dtype}")
print_param_dtype(model)
```
### 模型转换:float16
将模型转换为另一种精度。
```python
# float 16
model_fp16 = DummyModel().half()
#检查参数的数据类型。
print_param_dtype(model_fp16)
model_fp16
#使用模型进行简单推理。
import torch
dummy_input = torch.LongTensor([[1, 0], [0, 1]])
# 使用 float32 模型进行推理
logits_fp32 = model(dummy_input)
logits_fp32
# 使用 float16 模型进行推理
try:
logits_fp16 = model_fp16(dummy_input)
except Exception as error:
print("\033[91m", type(error).__name__, ": ", error, "\033[0m")
```
### 模型转换:bfloat16
关于 deepcopy 的注意事项:copy.deepcopy 会创建一个与原始模型独立的副本。对副本所做的修改不会影响原始模型,因为您创建的是一个“深拷贝”。有关更多详细信息,请参阅 Python 文档中关于 copy 库的内容。
```python
from copy import deepcopy
model_bf16 = deepcopy(model)
model_bf16 = model_bf16.to(torch.bfloat16)
print_param_dtype(model_bf16)
logits_bf16 = model_bf16(dummy_input)
#现在,比较 logits_fp32 和 logits_bf16 之间的差异。
mean_diff = torch.abs(logits_bf16 - logits_fp32).mean().item()
max_diff = torch.abs(logits_bf16 - logits_fp32).max().item()
print(f"Mean diff: {mean_diff} | Max diff: {max_diff}")
```
### 使用不同数据类型的流行生成模型
加载[Salesforce/blip-image-captioning-base](https://huggingface.co/Salesforce/blip-image-captioning-base)以进行图像字幕生成。
要获取 Younes 提供的示例代码:
点击 "Model Card" 选项卡。
在右侧,点击 “<> Use in Transformers” 按钮,您将看到一个弹出窗口,内含加载此模型的示例代码。
```python
# 直接加载模型
from transformers import AutoProcessor, AutoModelForSeq2SeqLM
processor = AutoProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = AutoModelForSeq2SeqLM.from_pretrained("Salesforce/blip-image-captioning-base")
#要查看带有示例的代码,请点击弹出窗口底部的 "Read model documentation"。它会打开一个新标签。https://huggingface.co/docs/transformers/main/en/model_doc/blip#transformers.BlipForConditionalGeneration
# 在页面中稍微向下滚动,越过 "parameters" 部分,您会看到 "Examples:"。
from PIL import Image
import requests
from transformers import AutoProcessor, BlipForConditionalGeneration
processor = AutoProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "A picture of"
inputs = processor(images=image, text=text, return_tensors="pt")
outputs = model(**inputs)
#检查模型的默认数据类型
from transformers import BlipForConditionalGeneration
model_name = "Salesforce/blip-image-captioning-base"
model = BlipForConditionalGeneration.from_pretrained(model_name)
# inspect the default data types of the model
# print_param_dtype(model)
#检查模型的内存占用。
fp32_mem_footprint = model.get_memory_footprint()
print("Footprint of the fp32 model in bytes: ", fp32_mem_footprint)
print("Footprint of the fp32 model in MBs: ", fp32_mem_footprint/1e+6)
#以 bfloat16 加载相同的模型。
model_bf16 = BlipForConditionalGeneration.from_pretrained(
model_name,
torch_dtype=torch.bfloat16
)
bf16_mem_footprint = model_bf16.get_memory_footprint()
# 获取相对差异
relative_diff = bf16_mem_footprint / fp32_mem_footprint
print("Footprint of the bf16 model in MBs: ", bf16_mem_footprint/1e+6)
print(f"Relative diff: {relative_diff}")
```
### 模型性能:float32 vs bfloat16
现在,比较两种模型的生成结果。
```python
from transformers import BlipProcessor
processor = BlipProcessor.from_pretrained(model_name)
#加载图像。
from helper import load_image, get_generation
from IPython.display import display
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
image = load_image(img_url)
display(image.resize((500, 350)))
results_fp32 = get_generation(model, processor, image, torch.float32)
print("fp32 Model Results:\n", results_fp32)
results_bf16 = get_generation(model_bf16, processor, image, torch.bfloat16)
print("bf16 Model Results:\n", results_bf16)
#对于 Hugging Face Transformers 库,默认的数据类型是 float32。您可以将 "默认数据类型" 设置为您所需要的
desired_dtype = torch.bfloat16
torch.set_default_dtype(desired_dtype)
dummy_model_bf16 = DummyModel()
print_param_dtype(dummy_model_bf16)
#同样,您可以将默认数据类型重置为 float32。
torch.set_default_dtype(torch.float32)
print_param_dtype(dummy_model_bf16)
```
### 注意
您刚刚使用了一种简单的量化形式,将模型的参数保存为更紧凑的数据类型(bfloat16)。在推理过程中,模型在这种数据类型下执行计算,其激活也是在这种数据类型下进行的。
在下一课中,您将使用另一种量化方法 "线性量化",该方法通过在推理过程中从压缩的数据类型转换回原始的 FP32 数据类型,使量化模型的性能更接近原始模型。
## Class 4:量化理论
在本实验中,您将执行 Linear Quantization(线性量化)。
这是最流行的量化方案,他用于大多数最先进的量化方法。
然后,我们将使用Huggingface的量化工具包Quanto将线性量化应用在真实模型。
量化是将大型的set映射到一小部分值的过程。量化有很多种,在本节课,我们将重点介绍线性量化,让我们来看看如何对简单张量执行8位量化,我们将从float32变为8-int
让我们先来看看这个随机数矩阵,他的数据是float32类型,我们该如何在不丢失太多信息的情况下将float32权重转换为int8权重呢

你可以将此矩阵中最大的数(在这是728.6)映射到int8可以存储的最大值(127)
同样,您可以将此矩阵的最大负数(在本例中为负 184)映射到 int8 可以存储的最小值,即负 128。

我们还可以按照线性映射映射其余值进行映射。

ok这就是简单量化了张量。
接下来,就可以删除原始张量以释放空间,最终我们会得到量化的张量以及用于执行线性映射的参数s和z。“s”代表比例尺,“z”代表零点,到这里,看上去我们节省了很多空间,但我们要怎么得到原来的数据呢?
答案是我们没办法得到与原始张量完全相同的张量,但是你可以使用遵循用于量化原始张量的线性关系的量化
#### 需要安装的库
如果您在本地机器上运行,可以安装以下内容:
```python
!pip install transformers==4.35.0
!pip install quanto==0.0.11
!pip install torch==2.1.1
```
> 请注意,由于硬件内存限制,为了向所有人免费提供本课程,您将在此处运行的代码适用于 T5-FLAN 模型,而不是 EleutherAI AI Pythia 模型。
> 对于 T5-FLAN 模型,如果您在本地运行,这里还有一个需要安装的库:
```python
!pip install sentencepiece==0.2.0
```
#### 不进行量化
```python
model_name = "google/flan-t5-small"
import sentencepiece as spm
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-small")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-small")
input_text = "Hello, my name is "
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
from helper import compute_module_sizes
module_sizes = compute_module_sizes(model)
print(f"The model size is {module_sizes[''] * 1e-9} GB")
```
#### 量化模型(8位精度)
```python
from quanto import quantize, freeze
import torch
quantize(model, weights=torch.int8, activations=None)
print(model)
```
#### 冻结模型
```python
freeze(model)
module_sizes = compute_module_sizes(model)
print(f"The model size is {module_sizes[''] * 1e-9} GB")
```
#### 在量化模型上尝试运行推理
```python
input_text = "Hello, my name is "
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
#### 不进行量化
```python
#加载EleutherAI/pythia-410m模型和tokenizer。
from transformers import AutoModelForCausalLM
model_name = "EleutherAI/pythia-410m"
model = AutoModelForCausalLM.from_pretrained(model_name, low_cpu_mem_usage=True)
print(model.gpt_neox)
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
#编写一个(文本)句子的开头,让模型完成。
text = "Hello my name is"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=10)
outputs
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
#使用helper函数compute_module_sizes计算模型的大小。
from helper import compute_module_sizes
module_sizes = compute_module_sizes(model)
print(f"The model size is {module_sizes[''] * 1e-9} GB")
print(model.gpt_neox.layers[0].attention.dense.weight)
```
#### 8位量化
```python
from quanto import quantize, freeze
import torch
quantize(model, weights=torch.int8, activations=None)
# 执行量化后
print(model.gpt_neox)
print(model.gpt_neox.layers[0].attention.dense.weight)
# 冻结模型
freeze(model)
print(model.gpt_neox.layers[0].attention.dense.weight)
# 获取量化后模型的大小
module_sizes = compute_module_sizes(model)
print(f"The model size is {module_sizes[''] * 1e-9} GB")
# 量化模型后运行推理
outputs = model.generate(**inputs, max_new_tokens=10)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
### 比较“线性量化”与“降级”
回顾一下本课中的“线性量化”方法与上一课中的“降级”方法之间的区别:
当降级一个模型时,您将模型的参数转换为更紧凑的数据类型(bfloat16)。在推理过程中,模型使用这种数据类型进行计算,其激活也是这种数据类型。降级可能适用于bfloat16数据类型,但使用任何更小的数据类型可能会导致模型性能下降,并且如果您转换为整数数据类型(如本课中的int8),则无法工作。
在本课中,您使用了另一种量化方法,“线性量化”,它使得量化模型在推理过程中从压缩数据类型转换回原始的FP32数据类型,从而保持性能更接近原始模型。因此,当模型进行预测时,它是用FP32进行矩阵乘法,激活也是FP32。这使得您可以将模型量化为比bfloat16更小的数据类型,例如本例中的int8。
### 这只是开始…
这门课程旨在作为量化领域的入门介绍。🐣
如果您喜欢这门课程,您可以考虑给出评分,并分享您喜欢的内容。💕
如果您不喜欢这门课程,您也可以分享一下您认为可以改进的地方。🙏
## Class 5:量化LLMs
在本节课上,我们将看看将最先进的量化应用于大语言模型。例如,量化是否可以帮助我们微调LLM?毫无疑问,答案是肯定的。让我们看看该如何操作。
就像我们之前所说,量化是关于以某种方式压缩模型权重。
近期的一些SOTA(State-of-the-Art)量化方法,包括:
- LLM.INT8(仅8位)- Aug 2022 - Dettmers et al.
- QLoRA(仅4位)- May 2023 - Dettmers et al.
- AWQ - Jun 2023 - Lin et al.
- GPTQ - Oct 2022 - Frantar et al.
- SmoothQuant - Nov 2022 - Xiao et al.
三种最新的SOTA(State-of-the-Art)量化方法,分别是:
- QuIP# - Jul 2023 - Tseng et al.
- HQQ - November 2023 - Badri et al.
- AQLM - Feb 2024 - Egiazarian et al.
这些方法的设计目标是使LLMs更小、更快,同时最小化性能下降。它们都是开源的。
一些量化方法需要校准(也见上一课)
校准:
- 在数据集上进行推理
- 优化量化参数以最小化量化误差
许多量化论文都应用于LLM。
如果你将这些方法应用于其他模型(而不是LLM),你可能需要调整量化方法。
一些量化方法可以直接应用于任何模型而无需调整。
例如,自然语言处理、计算机视觉、音频、多模态。
“Ready to use”,(“out of the box”) 量化方法:
- Linear quantization (covered in this course)
- LLM.INT8 (only 8-bit)
- QLoRA (only 4-bit)
- HQQ (up to 2-bit)
Llama2 70B是一个70B参数的模型,例如Llama2 70B。它以32位精度在FP32中存储了280GB的数据。如果以4位精度存储,则可以减少到40GB。因此,存储大小减少了约7倍(280GB/40GB)。
Llama2 7B是一个7B参数的模型。它以32位精度在FP32中存储了28GB的数据。如果以4位精度存储,则可以减少到约4GB,并且这种格式被称为“GGUF”。该模型可以在计算机上运行。
#### 微调量化模型的好处,具体包括:
从量化中恢复准确性
为特定用例和应用程序定制模型。
以量化版本最佳执行的方式微调模型。
- 与训练后量化 (PTQ) 技术不兼容。
- 本课程中学到的线性量化方法是训练后量化的一个示例。
## 结论
恭喜你完成了这个短期课程,你已经了解了机器学习中一些常见的表示数据类型,例如整数和浮点数,以及如何使用不同的数据类型加载AI模型。
你还了解到了模型量化背后的基本概念,以及线性量化的工作原理。
你使用Quanto库以8位精读量化任何pytorch模型。然后,我们了解了量化的一些应用LLMs,例如最近最先进的量化方法LLMs。
有了这些知识,你将能够更好地了解模型压缩,并为你的使用选择最佳的量化技术💡
点赞
回复
X